
Amazon Textract is a highly scalable machine learning service that collects printed text, handwriting, and other information from scanned documents automatically.
Using Amazon Textract, you can easily extract text and data from images and any scanned documents that go beyond simple optical character recognition (OCR) to extract data from tables and forms.
Many businesses and government organizations extract data from scanned documents, such as PDFs, tables, and forms, through manual data entry that is slow, expensive, and prone to errors. Some businesses and government organizations are using simple business process automation (BPA), which provides fully automated workflows or semi-automated processes in the majority of businesses within various domains. These processes require manual configuration which needs to be updated each time the form changes to be usable. Textract uses machine learning to handle any type of document in real-time, accurately extracting text, forms, and tables without the need for any operator intervention or custom code.
Amazon Textract consists of higher capabilities than the average optical character recognition (OCR) system. It is able to extract information like names, birthdates, and social security numbers from the images and PDF files that are stored in the S3 buckets.
“Amazon Textract is built on the same highly scalable, proven deep-learning technology that Amazon’s computer vision scientists use to analyze billions of photos and movies every day.” It can be used without any prior knowledge of machine learning.”
Let’s explore AWS Textract!
In this exercise, we will be utilizing the following AWS services:
- Simple Storage Service (S3)
- Identity Access Management Service (IAM)
- Lamda Service
- Textract Service
We will be demonstrating one major use case of AWS Textract service using AWS Lambda with Python implementations:
Extracting Text from an S3 Bucket Image (Hands-On)
Adding boto3
In order to use AWS Textract in Python, the latest boto3 package is required. This package we will download and upload as an AWS Lambda “Layer”.
Execute the following command in the command shell.
pip install boto3
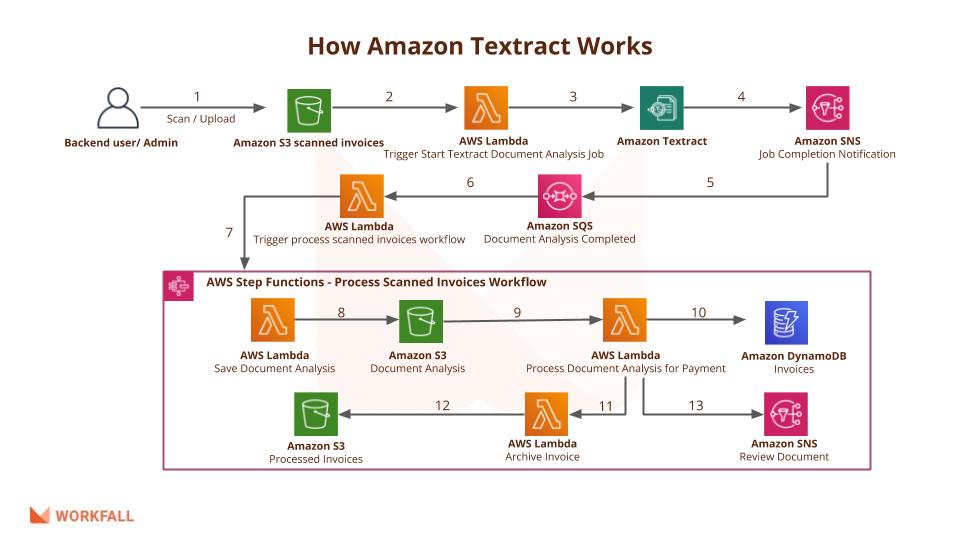
Now let’s create a boto3 layer. Go to AWS Lambda -> Layers and click “Create Layer”.
Give a layer name, select the latest Python version and upload the zip file as below.
So, let’s start doing text extraction!
- Extracting Text from the image stored in the S3 bucket
We are going to create a Lambda function that gets triggered whenever an image gets uploaded to S3 Bucket.
1.1 Creating the S3 Bucket
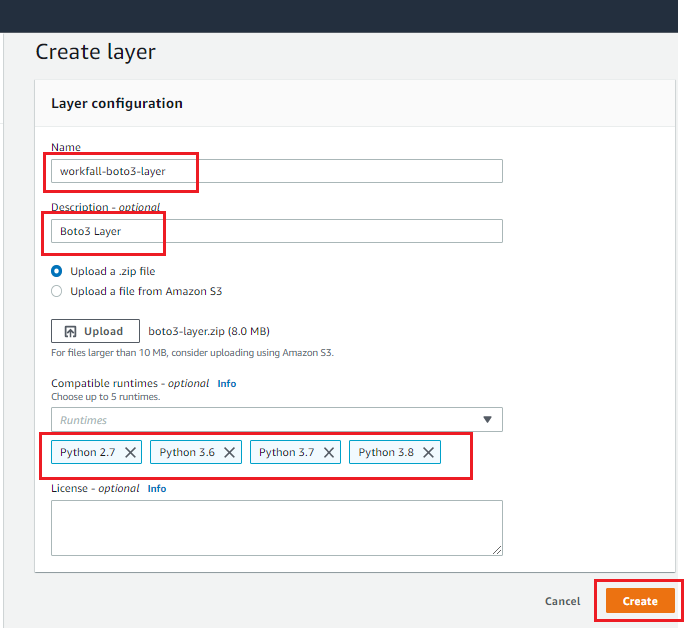
In the Amazon console, go to the AWS S3 page and click “Create bucket”.
Enter Bucket name and Region same as the region that will be used in Lambda function, in the Set permissions section, set the permissions as below image and create a bucket
1.2 Creating The S3 Lambda Trigger
Now we’ll write a Lambda function that will be called whenever a new image is uploaded to the bucket we built.
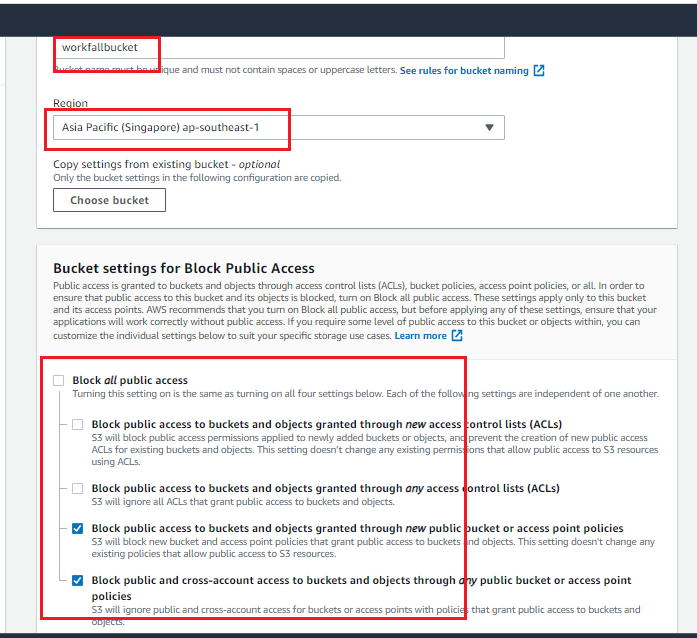
Click “Create function” on the AWS Lambda service page.
- Select “Use a blueprint” and search for “s3-get-object-python” template and click “Configure” as shown in the below image:
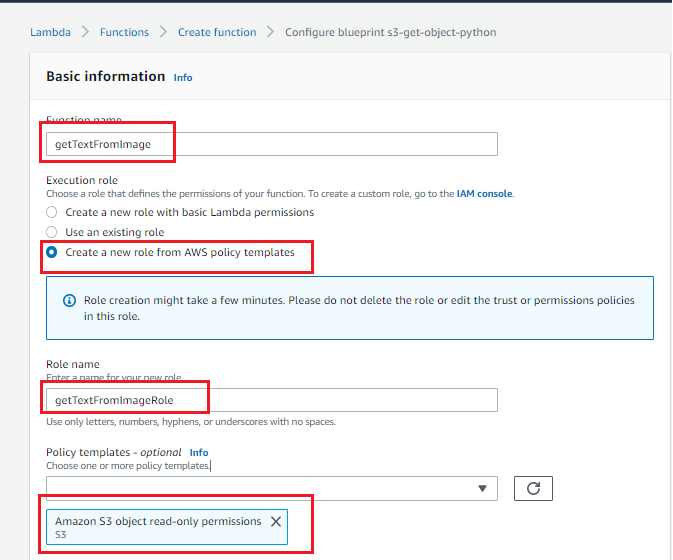
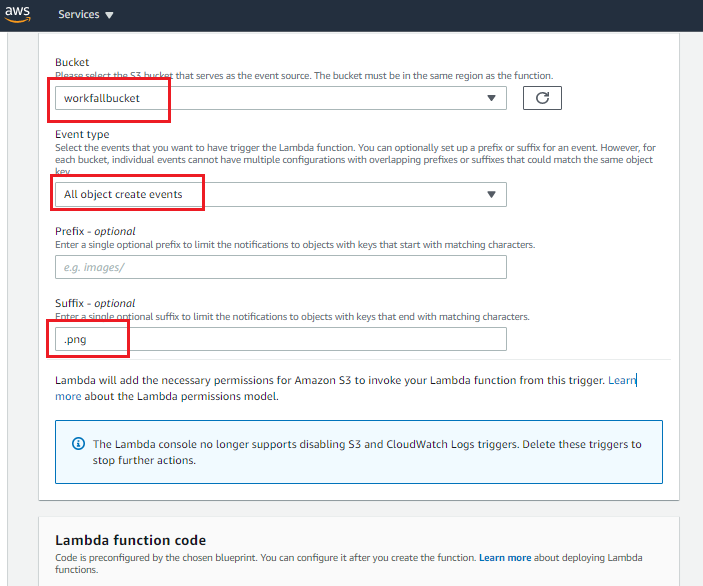
- Enter “Function name”, “Role name” and select the “Bucket name” as the S3 bucket created in the previous step. Add “Suffix” to restrict the trigger only for PNG images. Fill out the rest of the settings as shown in the below image. Don’t change Lambda function code as of now, we will do the changes later in the code. Click on the “Create function” button.
Replace the existing code in the Function Code area with the following line of code. This code sends the uploaded image to the AWS Textract and writes the response as a text file with the same name to the S3 bucket.
1.3 Attaching Permission Policies to Lambda
In the Lambda setup, go to the Permission tab and select “getTextFromImageRole.” as displayed in below image:
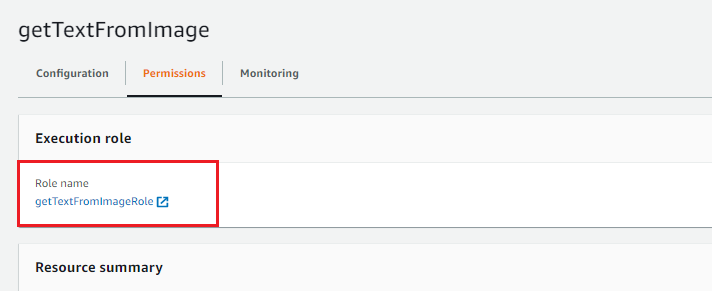
This will open the “getTextFromImageRole” configuration page as below.

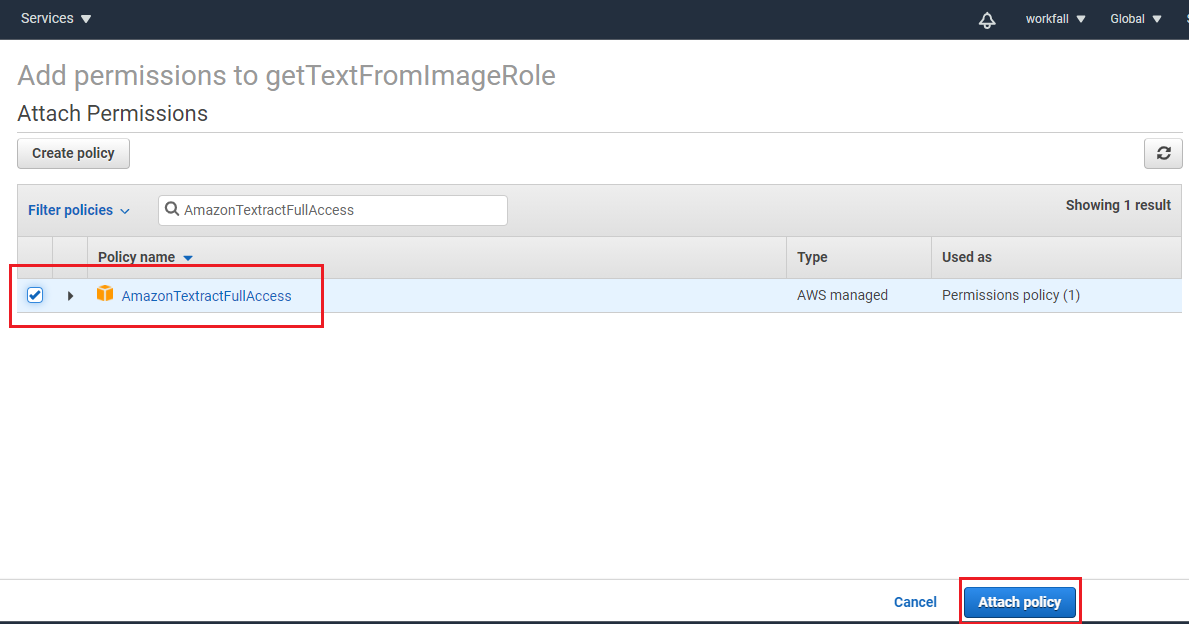
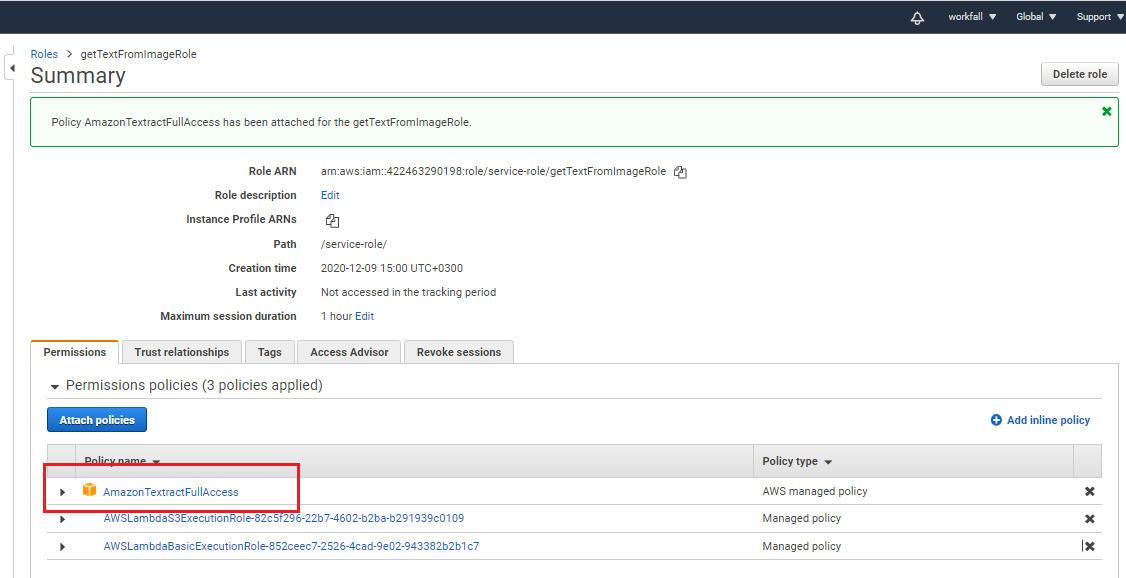
Click “Attach policy” and select “AmazonTextractFullAccess” policy and click “Attach policy” as displayed in the below image.
This will give Lambda function permission to access AWS Textract service as shown in the following image
1.4 Adding Custom “boto3-layer” to Lambda
Click “Layers” from Lambda designer and click “Add a layer” as shown in the below image

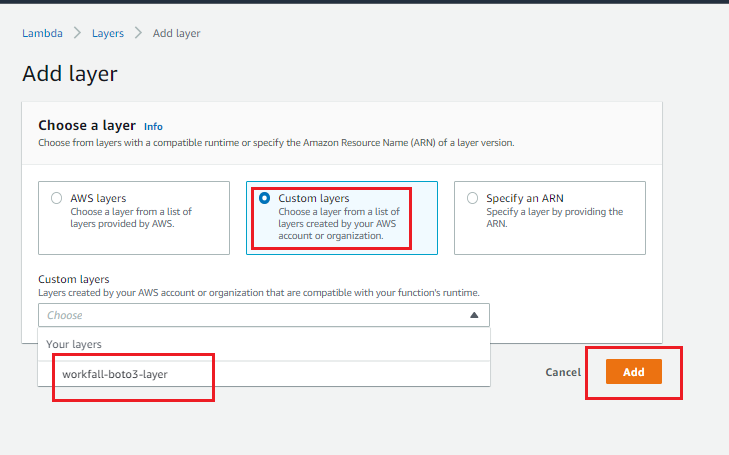
It will show the Add Layer screen as shown in the following image. Select Custom Layer and add the “workfall-boto3-layer” that was created earlier and click on Add button
1.5 Testing The S3 Lambda Trigger
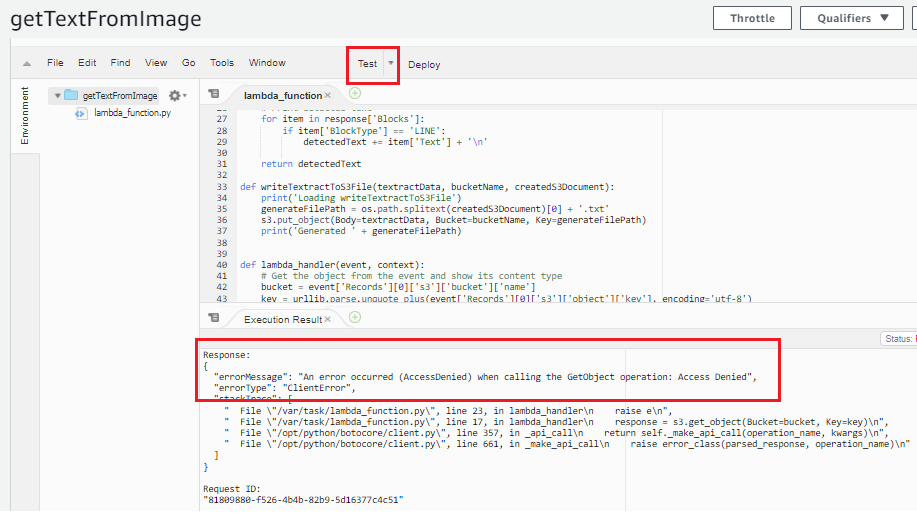
Before uploading the files into S3 bucket, let’s test our Lambda function. Click on “Test”, as of now we are getting some errors as shown in the following image. This error is regarding access denied on the GetObject operation.
Let’s fix this error. Go to the permission tab of the Lambda function and click on the role named getTextFromImageRole. In the next screen, click on the “Add inline policy” to add a policy to give access to the lambda function to access objects as shown in the following image:
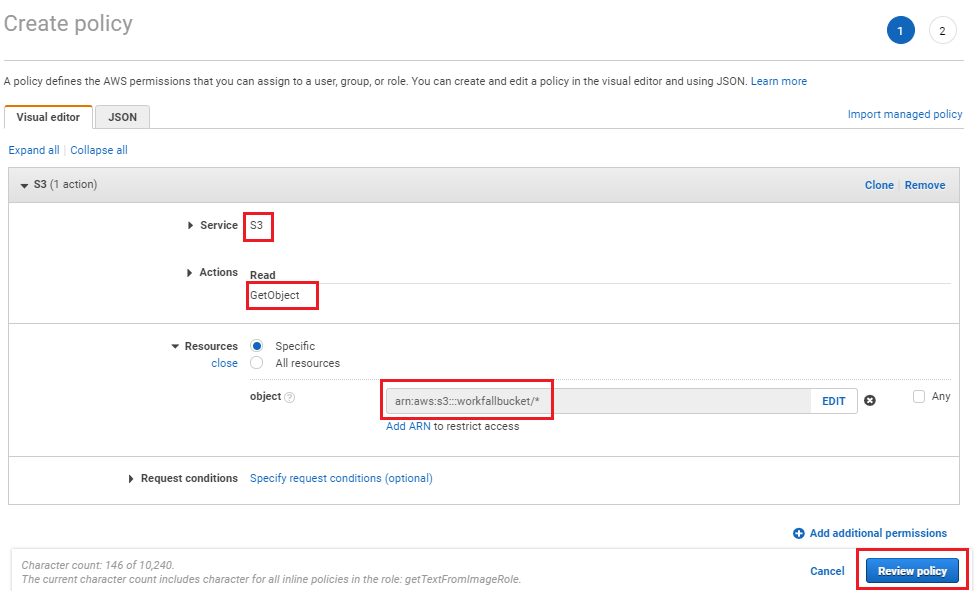
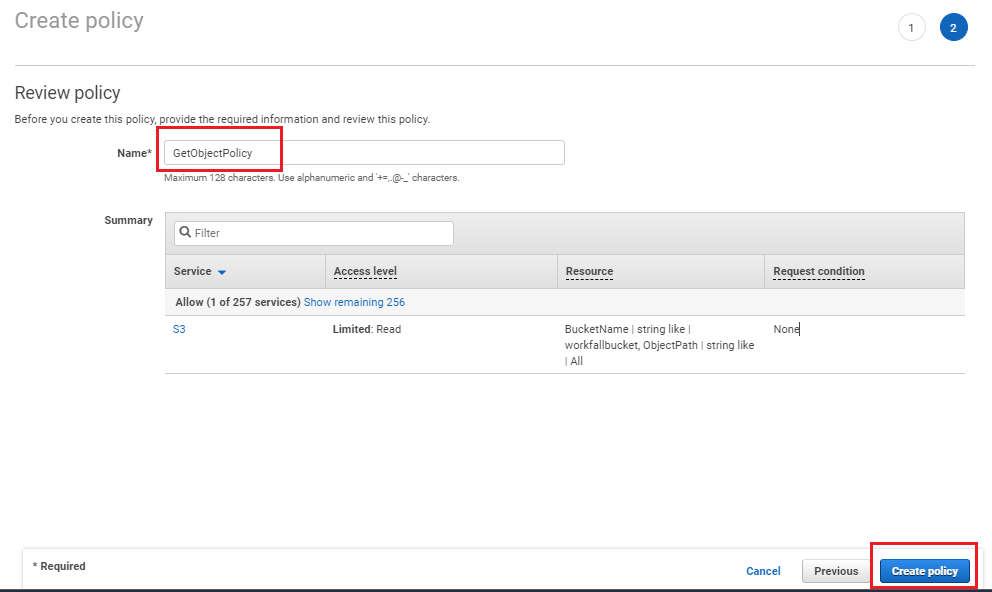
It will take you to the next screen as shown in the below image. Give a name to the policy and click on “Create Policy” button
Go to the S3 bucket “workfallbucket” created in the previous step and upload a png image with some text. I have uploaded the following image which represents the Workfall Partner Onboarding process.
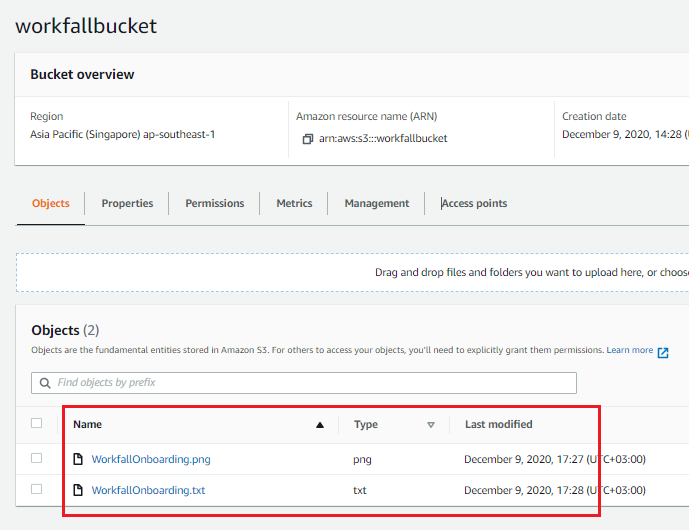
Once the image is uploaded, after a few seconds the extracted text file should be created in the same bucket with the same name as displayed in the following image:
Conclusion
In this blog, we learned about how to use AWS Textract to extract data from any Image & PDF. We will discuss more use cases of AWS Textract in our upcoming blogs. Stay tuned to keep getting all updates about our upcoming new blogs on AWS and relevant technologies.
Meanwhile …
Keep Exploring -> Keep Learning -> Keep Mastering
This blog is part of our effort towards building a knowledgeable and kick-ass tech community. At Workfall, we strive to provide the best tech and pay opportunities to AWS-certified talents. If you’re looking to work with global clients, build kick-ass products while making big bucks doing so, give it a shot at workfall.com/partner today.


