
Did you know that by the end of 2024, more than 75% of companies will have operationalized AI? One of the fundamental procedures that support the operationalization of AI is MLOps. By 2025, the market for MLOps is expected to boom up to USD 4 billion as per a Forbes study. MLOps is a combination of Machine Learning, DevOps, and Data Engineering practices. It helps organizations to reliably and efficiently install and manage ML systems in production.
MLOps professionals have been in short supply, which makes their demand in the market pretty high. The average estimated salary that an MLOps Engineer earns is USD 90,529 according to Glassdoor. It is partly due to the fact that many data scientists consider ML model constructions as the end of their labor. It is an MLOps Engineer who makes these models available to the end-users. They are responsible for testing, logging, and scaling these models once deployed.
Although it is easier for software professionals to take MLOps Engineering as a career choice, it turns out to be feasible even for someone who does not come from a technical background. By learning a selection of programming languages and imbibing data science skills, you can become an MLOps engineer, like many others in the field. Want to know how to kick-start your MLOps journey? Then this blog is for you!

In this blog, we will cover:
- What is Machine Learning?
- What are the different types of Machine Learning?
- Machine Learning-based Applications
- Change scenarios that must be managed
- Machine Learning Life Cycle
- Need for MLOps in Machine Learning Development
- What is MLOps?
- The Evolution of MLOps
- Features of MLOps
- MLOps Lifecycle
- How to implement MLOps?
- Continuous X
- Best Practices of MLOps
- DevOps VS MLOps
- From DevOps to MLOps
- ML Workflow
- Some good MLOps tools
- End-to-End MLOps Solutions
- Hybrid MLOps Infrastructure
- MLOps Engineers are on the rise
- What is an MLOps Engineer?
- Prerequisites of Becoming an MLOps Engineer
- Job Responsibilities of an MLOps Engineer
- Next Steps for the MLOps Engineer
- Conclusion
What is Machine Learning?
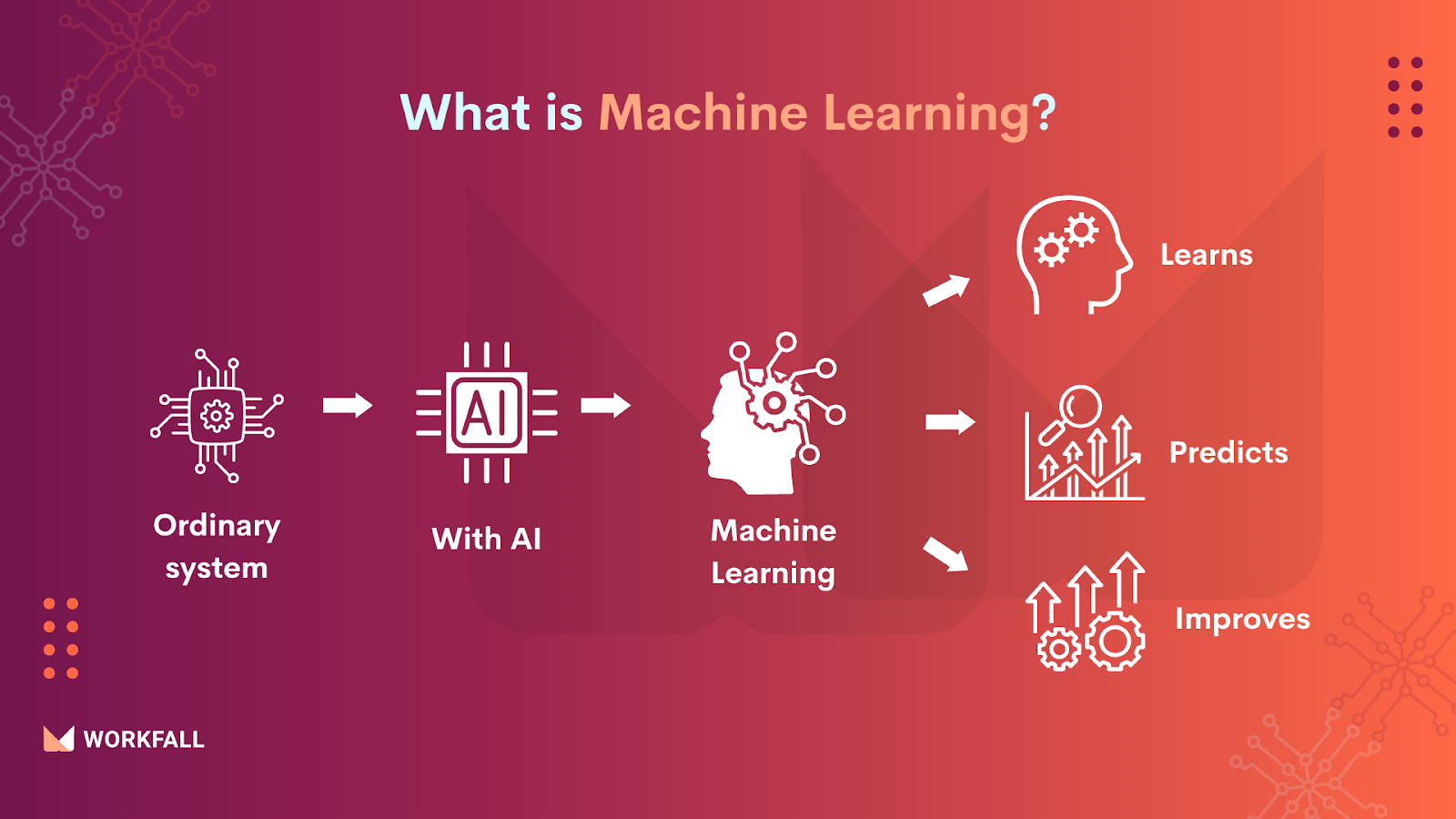
Machine learning (ML) is a kind of artificial intelligence (AI) that allows software applications to predict outcomes accurately without being expressly designed to do so. Machine learning algorithms forecast new output values using historical data as input.
Machine learning is commonly used in recommendation engines. Fraud detection, spam filtering, malware threat detection, business process automation (BPA), and predictive maintenance are some other popular use cases of Machine Learning.
Machine learning is significant because it allows businesses to see trends in customer behavior and business operating patterns while also assisting in the development of new goods. Machine learning is at the heart of many of today’s most successful businesses, like Facebook, Google, and Uber. Machine learning has become a critical competitive differentiator for many firms.
What are the different types of Machine Learning?
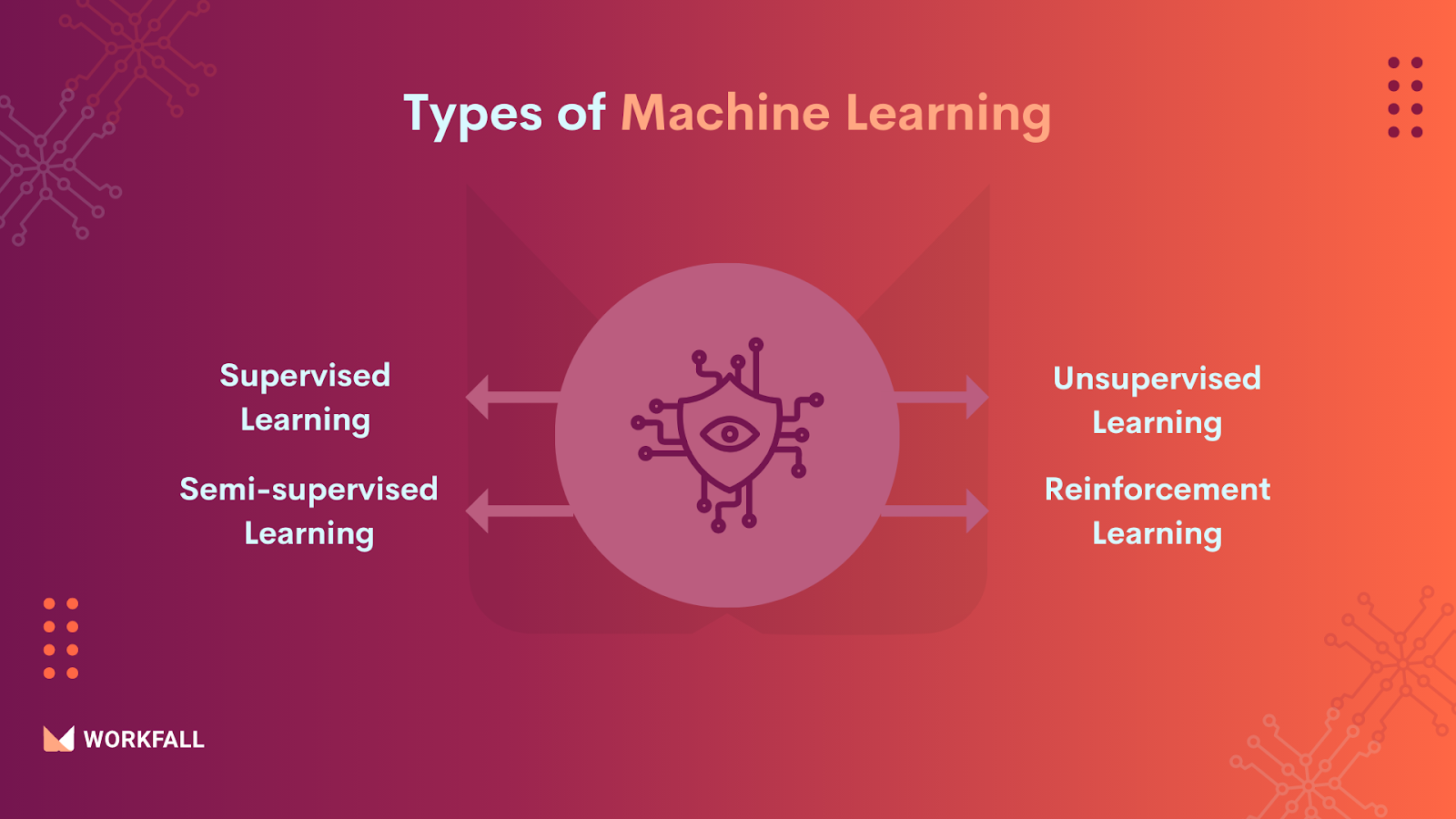
- Supervised Learning: In this type of machine learning, data scientists provide labeled training data to algorithms and specify the variables they want the programme to look for connections between. Both the input and output of the algorithm are supplied.
- Unsupervised Learning: Algorithms that train on unlabeled data are used in this sort of machine learning. The programme looks for links between data sets that are important. The data used to train algorithms, as well as the forecasts or suggestions they produce, are all predetermined.
- Semi-supervised Learning: This method of ML combines the 2 previous approaches. Although data scientists may feed an algorithm largely labeled training data, the model is allowed to explore the data and establish its own understanding of the set.
- Reinforcement Learning: Reinforcement learning is a technique used by data scientists to teach a machine to execute a multi-step procedure with precisely stated criteria. Data scientists create an algorithm to complete a task and provide it with positive or negative feedback as it learns how to do so. But, for the most part, the algorithm chooses which actions to take on it’s own.
Machine Learning-based Applications
Programmers automate tasks by writing programmes in the traditional software development process. In machine learning, a computer finds a program that fits data. By mining rules from data, machine learning complements traditional software development. Machine learning is highly beneficial in complex situations when handwriting the rules is next to impossible.

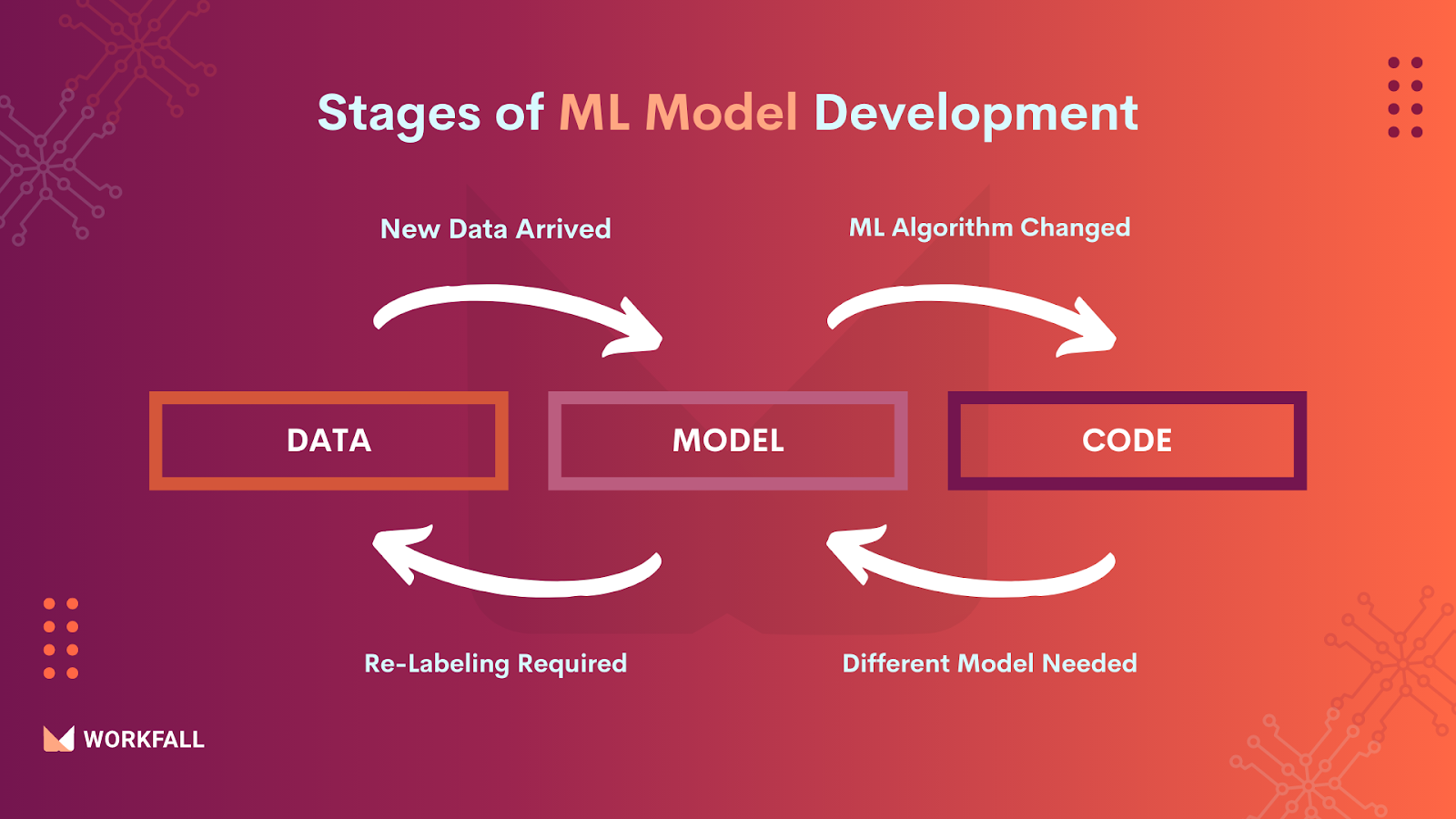
Change scenarios that must be managed
The reason for the previously mentioned deployment gap is that machine learning-based application development is fundamentally different from traditional software development. There are three stages of change in the development pipeline: data, machine learning model, and code. This means that in machine learning-based systems, a build could be triggered by a mix of code, data, or model changes. The “Changing Anything Changes Everything” idea is also known as this.
Machine Learning Life Cycle
Because the model and the outcome of training are related to the data on which they were trained, the machine learning lifecycle is data-driven. Following are the steps involved:
- Create an ML model: Based on the application, this stage determines the model type. It also discovers that the model’s application in the model learning stage allows them to be correctly developed according to the needs of an intended application. The Supervised model, Unsupervised model, classification models, regression models, clustering models, and reinforcement learning models are among the machine learning models accessible.
- Preparation of Data: For machine learning, a wide range of data can be used as input. This information can come from a variety of places, including businesses, pharmaceutical companies, Internet of Things devices, enterprises, banks, and hospitals, among others. Large amounts of data are provided throughout the machine’s learning stage because as the amount of data increases, the machine aligns itself to produce the desired outcomes. This output data can be analyzed or used as a seed in other machine learning applications or systems.
- Model Education: This step focuses on building a model from the data provided. A portion of the training data is utilized to find model parameters such as polynomial coefficients or machine learning weights, which serve to reduce error for the given data set. The model is then tested using the remaining data. These two procedures are usually done several times in order to improve the model’s performance.
- Parameter Choice: It entails the selection of the training parameters, often known as hyperparameters. The effectiveness of the training process is controlled by these parameters, and the model’s performance is ultimately determined by them. They are quite important for the machine learning model’s successful production.
- Learning Transfer: There are numerous advantages to reusing machine learning models across domains. Despite the fact that a model cannot be directly moved between domains, it is used as a starting point for training a subsequent model. As a result, the training time is greatly reduced.
- Verification of the Model: The trained model created by the model learning stage is the input to this step, and the output is a verified model that gives enough information for users to judge whether the model is appropriate for its intended application. As a result, this stage of the machine learning lifecycle is concerned with whether a model works effectively when given unknown inputs.
- Put the ML model into action: We apply to incorporate ML models into processes and applications at this level of the ML lifecycle. The ultimate goal of this stage is to ensure that the model works properly after deployment. The models should be installed in a way that allows them to be used for inference and that they are updated on a regular basis.
- Observation: It entails incorporating safety features to ensure the model’s proper operation throughout its lifespan. To accomplish this, adequate administration and upgrading are essential.

Need for MLOps in Machine Learning Development
Model management in production is difficult. Machine learning models must increase efficiency in business applications or support efforts to make better judgments as they run in production to maximize the value of machine learning. Businesses can use MLOps processes and technologies to deploy, administer, monitor, and govern machine learning. MLOps firms help businesses improve the performance of their models and accelerate the use of machine learning automation.
Important data science techniques are growing to include more model management and operations functions, ensuring that models do not have a detrimental influence on business by generating incorrect findings. Automating the process of retraining models with updated data sets is increasingly essential, as is spotting model drift and notifying when it becomes substantial. The model performance also includes maintaining the underlying technology, and MLOps platforms, and enhancing performance by recognizing when models require changes.
This does not imply that data scientists’ jobs are changing. Machine learning operations strategies are breaking down data silos and expanding the team. As a result, data scientists can focus on designing and deploying models rather than making business decisions, while MLOps engineers may manage ML that has already been deployed.
MLOps can help enterprises in a variety of ways:
- Scaling: MLOps is crucial for increasing the number of machine learning-driven apps in a company.
- Trust: MLOps also establishes trust for managing machine learning in dynamic situations by automating, testing, and validating the process. MLOps improves the consistency, legitimacy, and efficiency of machine learning development.
- Better use of data: MLOps can also transform how firms manage and profit from big data. MLOps shortens production life cycles by enhancing products with each iteration, resulting in more trustworthy insights that can be deployed more quickly. MLOps also allows for more focused feedback by assisting in the identification of what is simply noise and which anomalies require attention.
- Compliance: The regulatory and compliance aspect of operations is becoming increasingly crucial, especially as machine learning becomes more prevalent.
What is MLOps?
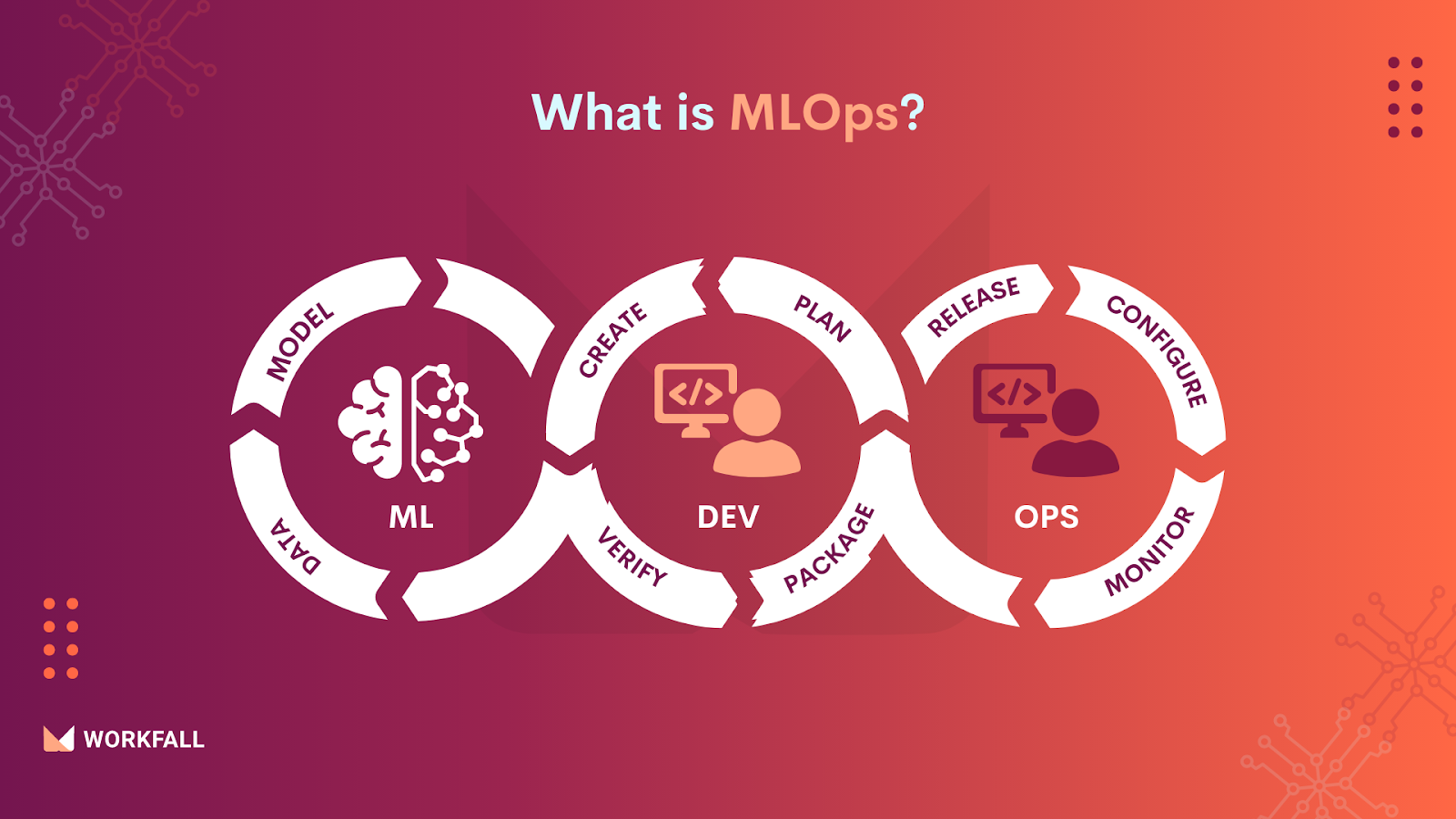
MLOps is a set of management techniques for the deep learning or production ML lifecycle, formed from machine learning or ML and operations or Ops. These include ML and DevOps methods, as well as data engineering processes for deploying and maintaining machine learning models in production.
Machine Learning Operations (MLOps) strategies and technology provide a managed, scalable way to deploy and monitor machine learning models in production environments. Businesses can use MLOps best practices to run AI successfully.
MLOps equips data scientists with quantitative standards as well as clear guidance and focuses on corporate interests.
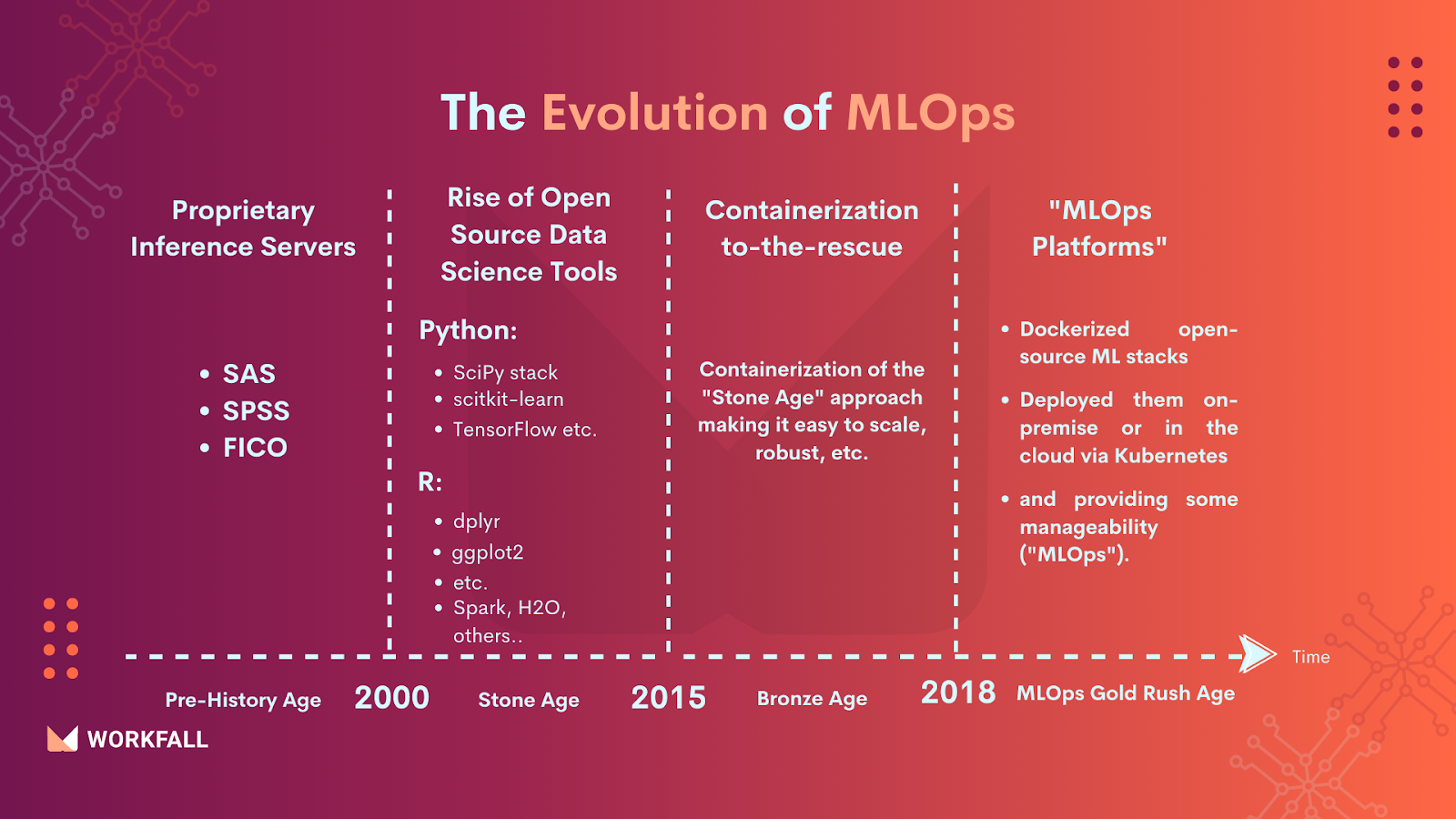
The Evolution of MLOps
The following shows the history of MLOps:
Features of MLOps
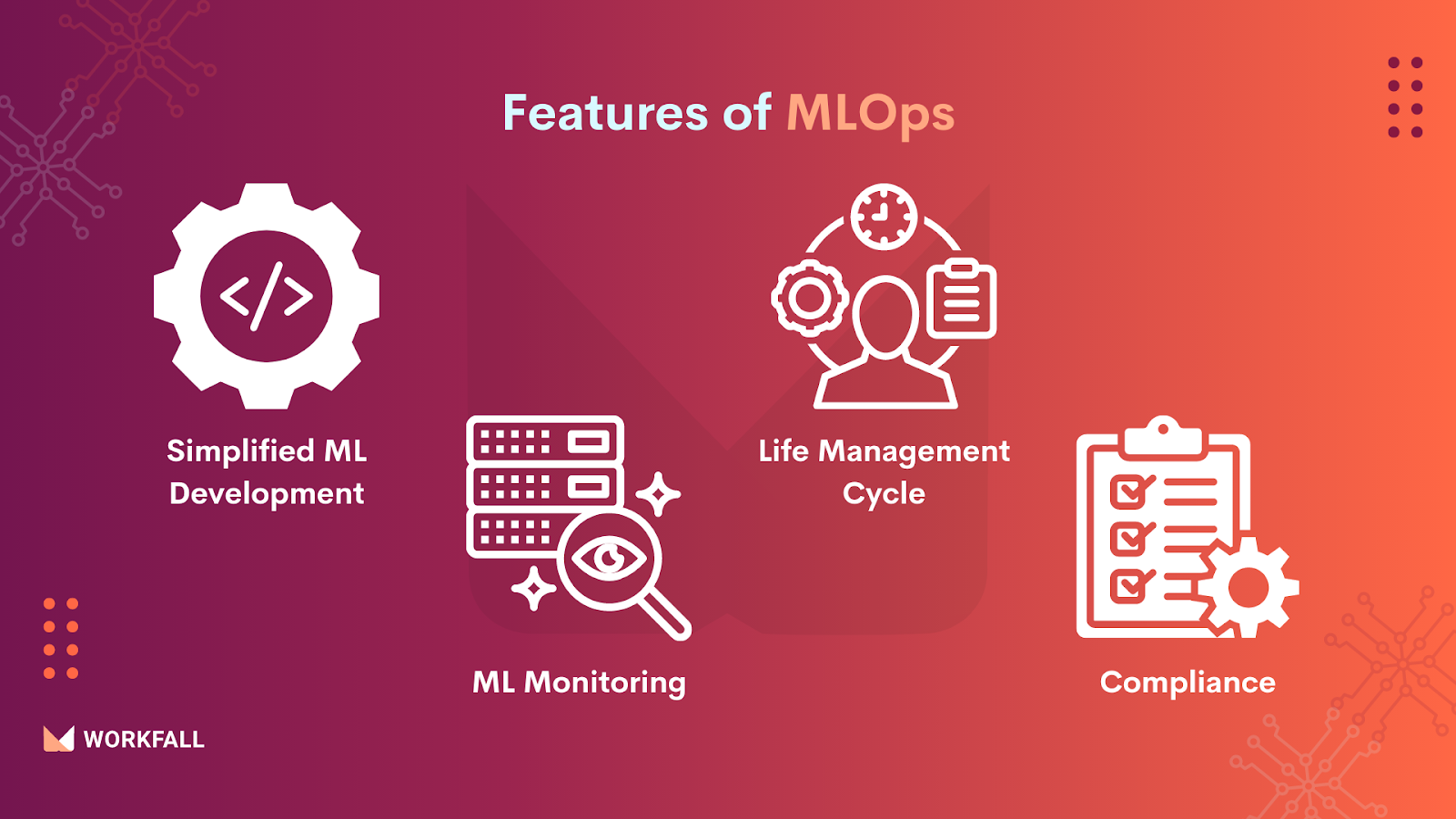
- Simplified ML Development: Data scientists may employ a variety of modeling frameworks, languages, and tools, making the deployment process more difficult. MLOps enables IT operations teams in production situations to deploy models from a variety of frameworks and languages more quickly.
- ML Monitoring: Monitoring machine learning monitoring does not operate with software monitoring tools. MLOps, on the other hand, is tailored for machine learning and provides model-specific metrics, data drift detection for essential features, and other core functions.
- Life management cycle: The first step in a long update lifetime is deployment. To keep a successful machine learning model, the team must test it and update it without impacting business applications; this is where MLOps comes in.
- Compliance: To reduce risk, avoid undesirable changes, and assure regulatory compliance, MLOps delivers traceability, access control, and audit trails.
MLOps Lifecycle

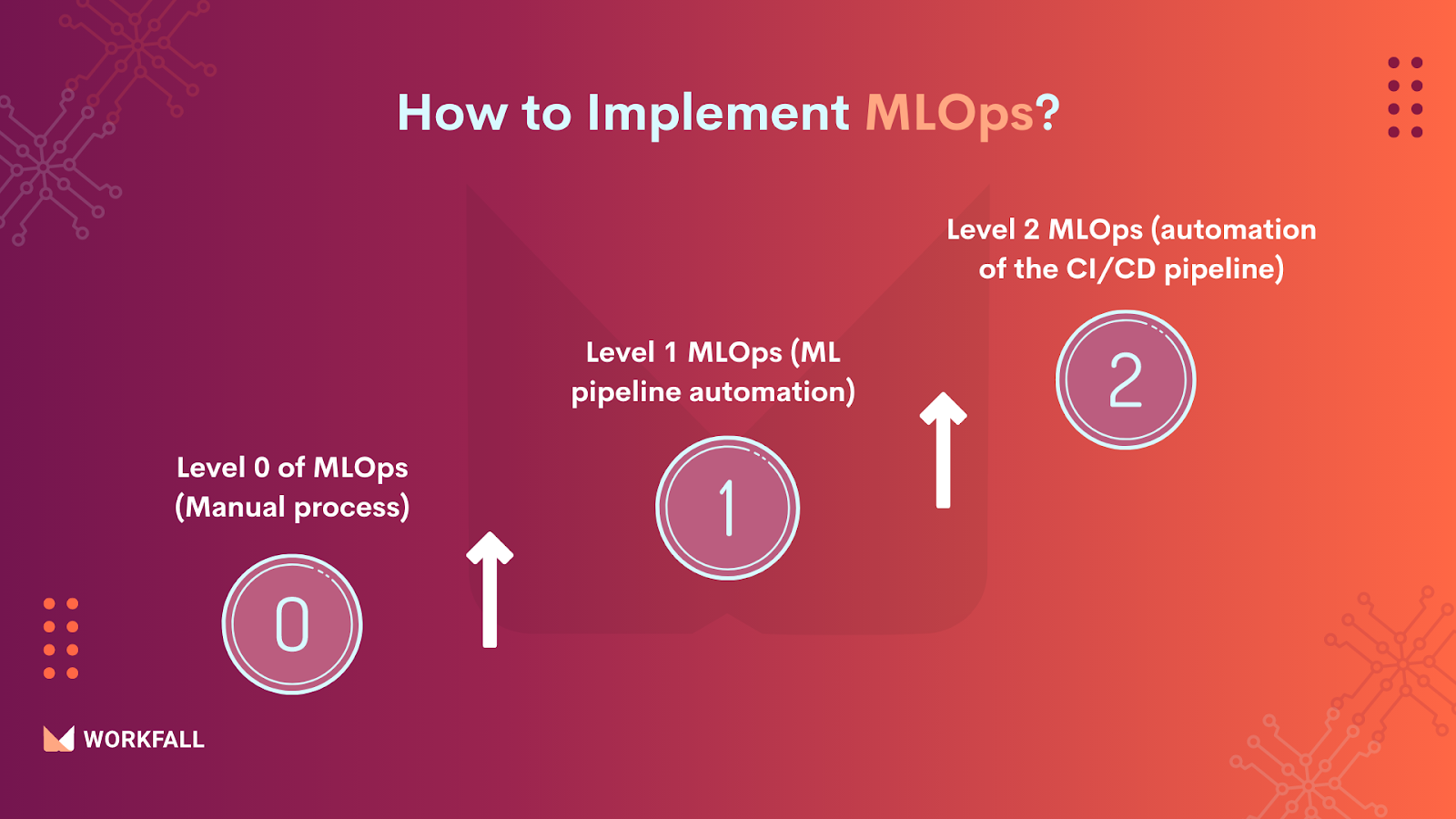
How to implement MLOps?
Continuous X
To comprehend Model deployment, we must first define “ML assets,” which include the ML model, its parameters and hyperparameters, training scripts, and training and testing data. These ML items’ identification, components, versioning, and dependencies are of interest to us. An ML artifact’s final destination could be a (micro-)service or infrastructure components. A deployment service ensures that the ML models, code, and data artifacts are stable by providing orchestration, logging, monitoring, and notification.
MLOps is a culture of machine learning engineering that encompasses the following practices:
- Continuous Integration (CI) adds data and models for testing and validating to the testing and validating code and components.
- Continuous Delivery (CD) challenges with the delivery of an ML training pipeline that installs another ML model prediction service automatically.
- Continuous Training (CT) is a property unique to machine learning systems that automatically retrain ML models for re-deployment.
- Continuous Monitoring (CM) concerns the monitoring of production data and model performance measures that are tied to business metrics.
Best Practices of MLOps
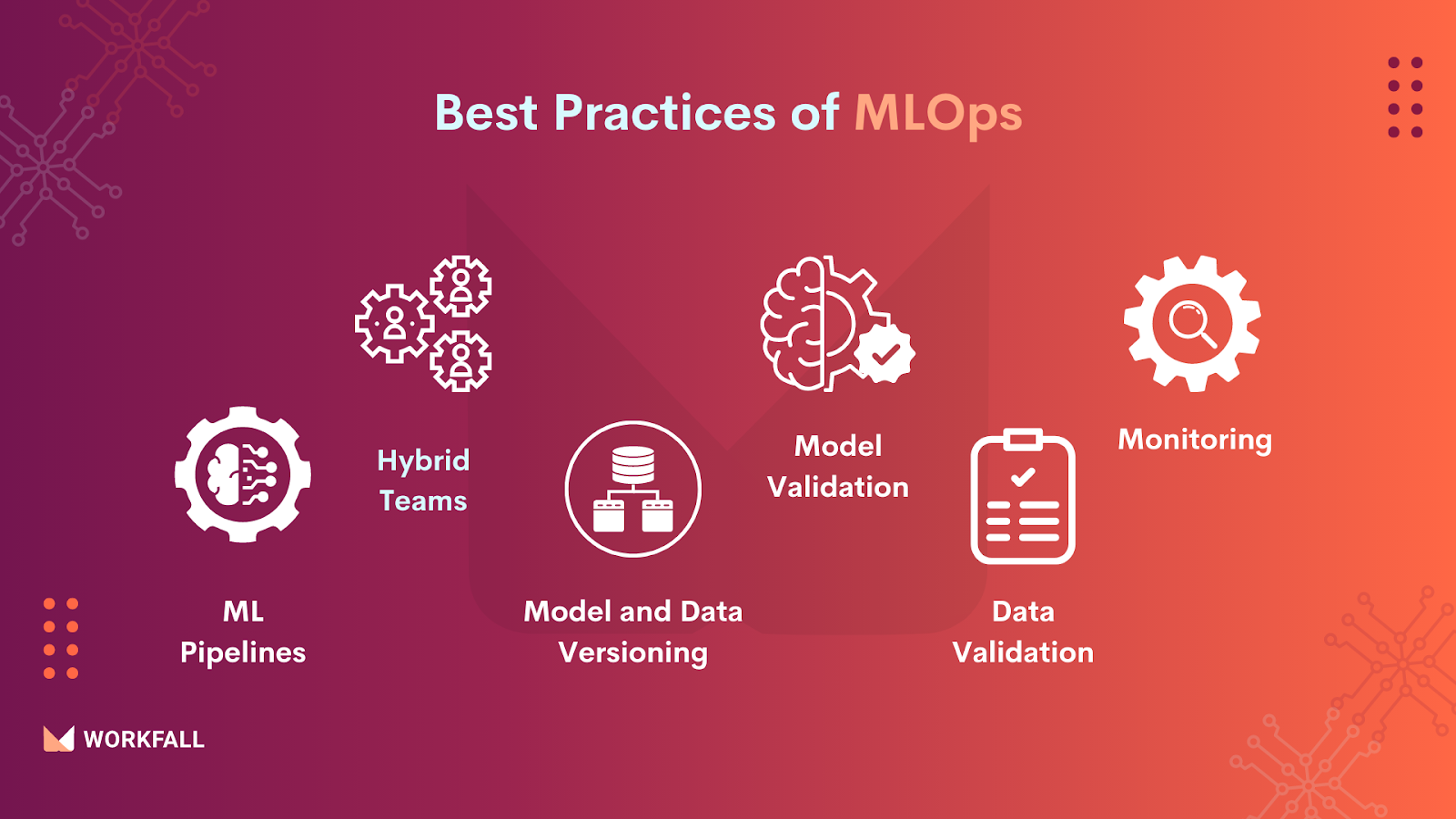
- ML Pipelines: The data pipeline is one of the most important ideas in Data Engineering. A data pipeline is a series of modifications made to data as it travels from its source to its destination. They’re commonly represented as a graph, with nodes representing transformations and edges representing dependencies or execution order.
- Hybrid Teams: A Data Scientist (ML Engineer), a Data Engineer, and a DevOps Engineer are the most likely members.
- Model and Data Versioning: In a conventional software world, you just require versioning code because it determines all behavior. Things are a little different in ML. We also need to keep model versions, the data needed to train it, and additional meta-information like training hyperparameters, in addition to the standard versioning code.
- Model Validation: Because no model can provide 100% correct outcomes, ML models are more difficult to evaluate than DevOps models. This means that rather than having a binary pass/fail status, model validation tests must be statistical in character.
- Data Validation: Validating the input data is usually the first step in a good data pipeline. ML pipelines require higher-level validation statistical features of the input, in addition to the basic validations that each data pipeline does. If the average diversion of a feature varies significantly from one training dataset to the next, the trained model and its predictions are likely to be affected.
- Monitoring: Monitoring becomes even more crucial for ML systems than it is for production systems. It’s because their performance is influenced not only by things over which we have some control, such as infrastructure and our own software but also by data, which we have less control over. As a result, we must monitor model prediction performance in addition to typical metrics like latency, traffic, errors, and saturation.
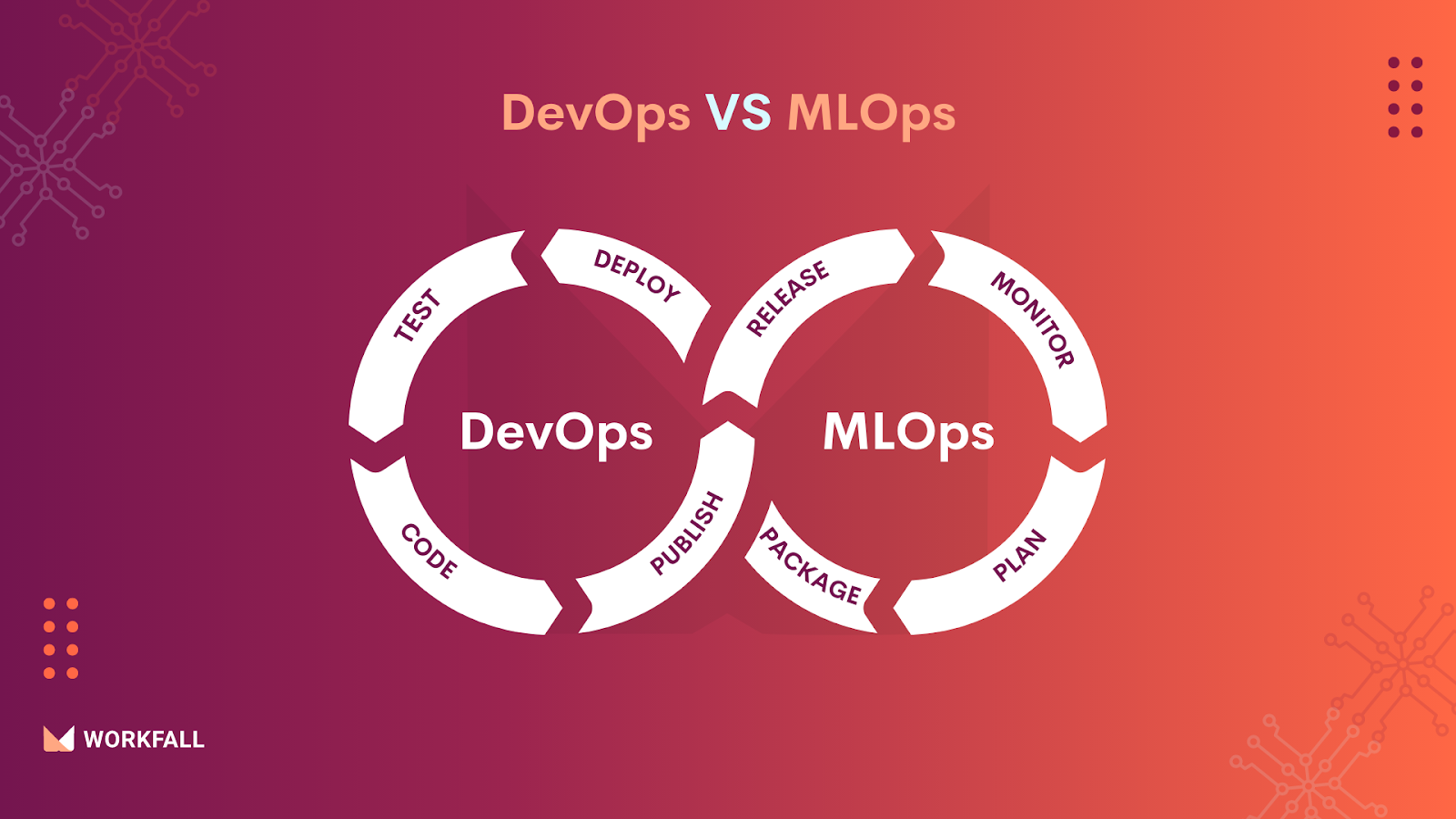
DevOps VS MLOps
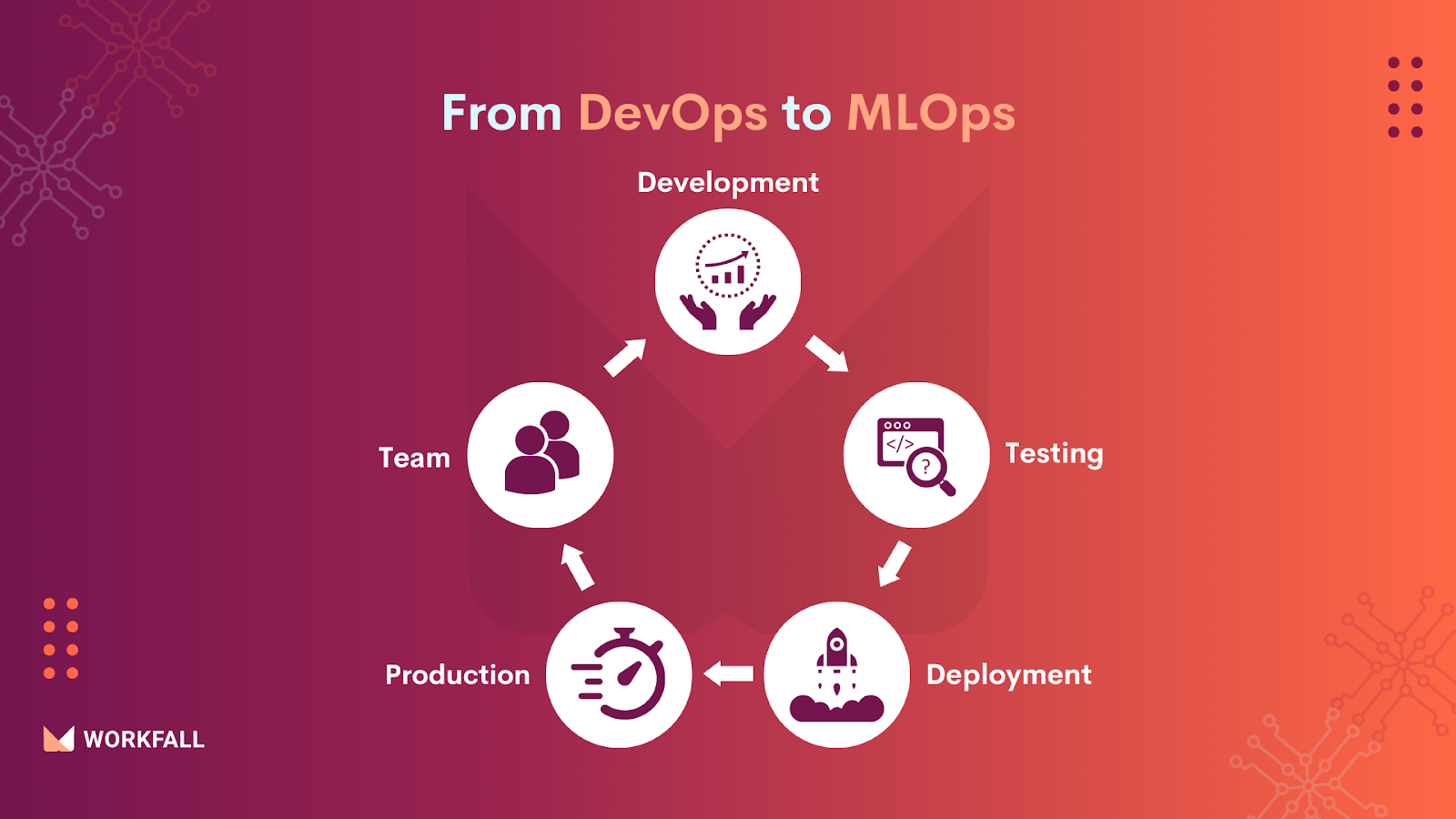
From DevOps to MLOps
ML systems differ from traditional software systems in a number of ways, which helps to differentiate DevOps from MLOps.
- Team: Data scientists who focus on model creation, exploratory data analysis, research, and experimentation are usually part of the team working on an ML project. These team members may not be as capable of producing production-class services as DevOps team members.
- Development: In each concept, “development” has two separate meanings.
You’ll often find code that constructs an application or interface on the traditional DevOps side. The code is subsequently packaged into an executable (artifact), which is then deployed and tested against a set of criteria. This cycle should ideally be automated and continue until the final product is ready.
The code is used to create/train a machine learning model in MLOps, on the other hand. The output artifact, in this case, is a serialized file that may be fed data and generate inferences. The validation process would involve comparing the training model to test data. Similarly, this is a cycle that repeats until the model achieves a specified level of performance.
- Testing: Testing an ML system is substantially more involved than testing conventional software systems. Both types of systems necessitate standard integration and unit tests, but ML systems also necessitate model validation, data validation, and the trained model’s quality evaluation.
- Deployment: For accurate predictions and results, ML models that have been trained offline are not simply implemented in real-world ML systems. Many scenarios necessitate a multi-step pipeline to retrain the model automatically before deployment. To build and deploy this type of machine learning project pipeline, data scientists must automate ML tasks that they perform manually before deployment, such as validating and training new models, which is a fairly difficult process.
- Production: ML models are more susceptible to decay than traditional software systems, such as continually changing data profiles and inefficient coding, and it is critical to account for this degradation and reduced performance. It’s vital to keep track of summary data statistics and monitor online model performance, and the system should be set up to detect values that differ from expectations and provide notifications or roll back when they happen.
ML Workflow

The steps taken during a machine learning deployment are defined by machine learning workflows. Machine learning workflows vary by project, but most contain four core phases.
- Data collection for machine learning: One of the most crucial steps in machine learning workflows is data collection. The project’s potential utility and accuracy are determined by the quality of the data you collect during data collection.
To collect data, you must first identify your sources before combining the data from those sources into a single dataset. This could include streaming data from the Internet of Things sensors, obtaining open-source data sets, or building a data lake out of various files, logs, or media.
- Pre-processing of data: You must pre-process your data once it has been collected. Cleaning, validating, and converting data into a usable dataset is all part of pre-processing. This may be a pretty simple operation if you are collecting data from a single source. If you’re combining data from many sources, make sure the data formats match, that the data is equally credible, and that any potential duplicates are removed.
- Creating data sets: This stage entails dividing the processed data into three datasets: training, validating, and testing:
- Training set: The training set is what is utilized to educate the algorithm on how to process information. This set uses parameters to define model categories.
- Validation set: Used to measure the model’s accuracy. The parameters of the model are fine-tuned using this dataset.
- Test set: The test set is used to evaluate the models’ accuracy and performance. This set is intended to reveal any model flaws or mistrainings.
- Refinement and training: You can start training your model after you have the datasets. This entails delivering your training data to your algorithm so that it may learn proper classification parameters and features.
After you’ve finished training, you can use your validation dataset to fine-tune the model. Changing or eliminating variables, as well as tweaking model-specific settings (hyperparameters), may be necessary until an acceptable level of accuracy is attained.
- Evaluation of machine learning: Finally, after you’ve discovered an appropriate collection of hyperparameters and optimized your model’s accuracy, you can put it to the test. Testing is done with your test dataset to ensure that your models use accurate features. You can return to training the model to enhance accuracy, alter output settings, or deploy the model as needed based on the feedback you receive.
Some good MLOps tools
The following image shows some of the good tools for MLOps:

End-to-End MLOps Solutions

These are fully managed services that allow developers and data scientists to swiftly create, train, and deploy machine learning models. The following are the best commercial solutions:
- Amazon Sagemaker is a toolkit for developing, training, deploying, and monitoring machine learning models.
If you want to build Machine Learning models quickly using Amazon Sagemaker, you can find our blog here:
Build Machine Learning Models Quickly Using Amazon Sagemaker
If you want to build ML models to generate accurate predictions without writing code using Amazon SageMaker Canvas, you can find our blog here:
- MLOps suite for Microsoft Azure:
- Azure Machine Learning allows you to create, train, and test repeatable machine learning pipelines.
- Azure Pipelines for ML deployment automation
- To track and evaluate metrics, use Azure Monitor.
- Azure Kubernetes Services, as well as other tools.
- The suite of Google Cloud MLOps:
- Dataflow for data extraction, validation, and transformation, as well as model evaluation
- To design and train models, use the AI Platform Notebook.
- Machine learning pipelines can be built and tested using Cloud Build.
- TFX will be deploying machine learning pipelines.
- Kubeflow Pipelines to organize machine learning deployments on Google Kubernetes Engine (GKE).
Hybrid MLOps Infrastructure
With the introduction of MLOps, new-age firms have moved their data centers to the cloud. This trend has demonstrated that firms seeking agility and cost efficiency in their infrastructure management can readily move to a fully-managed platform.
Hybrid MLOps capabilities are those that have some cloud interaction while also having some engagement with local computer resources. Laptops running Jupyter notebooks and Python scripts, HDFS clusters storing terabytes of data, online apps serving millions of people internationally, on-premises AWS Outposts, and a variety of other applications are examples of local compute resources.
In response to rising regulatory and data privacy concerns, many corporations and MLOps engineers are moving to hybrid solutions to handle data localization. Furthermore, an increasing number of smart edge devices are enabling the development of innovative new services in a variety of industries. Because these devices generate vast volumes of complex data that must be processed and assessed in real-time, IT directors must decide how and where that data will be processed.
MLOps Engineers are on the rise
When the industry recognized the problem was a lack of effective model deployment methods, they realized that they needed a completely new function – someone with machine learning and operational abilities who could handle the workflow that occurred after the model was built. This gave birth to the new role of MLOps Engineer!
What is an MLOps Engineer?
Model deployment and ongoing maintenance are the responsibility of an MLOps engineer.
You must be familiar with machine learning methods if you wish to work as an MLOps developer. You’ll be refactoring other data scientists’ code to make it production-ready, so you should be familiar with their work.
You must have a solid understanding of DevOps in addition to the machine learning expertise. DevOps is a role in which software engineers and operations teams collaborate to automate workflows. The position of an MLOps engineer is similar to that of a DevOps engineer, with the exception that the former works with machine learning models.
You’ll need to learn DevOps principles like workflow automation and CI/CD pipelines. Continuous Integration and Continuous Deployment, or CI and CD, allow data scientists’ code modifications to be delivered fast and reliably into production.
Prerequisites of Becoming an MLOps Engineer

- Knowledge of a Programming Language: Python is a good place to start because it is widely used by data scientists. Learning languages like C++ has the extra benefit of quicker runtime and extensive machine-learning library support.
- Server Administration: To work as an MLOps engineer, you must understand how servers operate. You should also become familiar with several operating systems, particularly Linux. If you don’t have a Linux operating system, you can start using a virtual computer like Ubuntu.
- Know Scripting: As an MLOps engineer, you’ll need to learn a scripting language to automate procedures. You can begin with Bash, which is one of the most widely used scripting languages today. Python, Go, and Ruby are popular programming languages for automating machine learning application deployment.
- Model Deployment: You’ll have to deploy machine learning apps to a production server as an MLOps engineer. A great way to start is making “Hello World” Python apps and practicing deploying them.
Also, the bulk of large companies uses cloud platforms to host their machine-learning applications. Most MLOps job advertising requests the expertise of AWS, Google Cloud Platform, and Microsoft Azure, which are three of the most popular cloud platforms today. So, select one of these platforms and learn how to launch and scale models using it.
- ML Algorithms and Models: You must comprehend the models you deal with as an MLOps developer. So, you should familiarize yourself with the frameworks used to create these models as well as the underlying machine learning technique.
To do so, you need to begin by studying the frameworks. Use Python frameworks like Scikit-Learn to create supervised and unsupervised learning models. Proceed to deep learning frameworks such as Keras, Tensorflow, and Pytorch. Learn about the different types of neural networks and how they can be employed (e.g., CNNs are primarily used for computer vision, and RNNs are used for sequence prediction). You’ll be ready for the data science part of the job once you understand the fundamentals of these models and frameworks.
- Databases: An MLOps engineer should be familiar with databases. They’ll have to build a database that can collect and store external data in real time. The output of the machine learning models may need to be saved for logging purposes, and the MLOps engineer will be responsible for managing and scaling the database system. Depending on your firm, you may utilize different types of databases, so make sure you know how to work with both SQL and NoSQL databases.
Job Responsibilities of an MLOps Engineer
- MLOps deployment and operationalization, with a focus on:
- Optimization of model hyperparameters
- Evaluation and explainability of models
- Automated retraining and model training
- Model onboarding, operations, and decommissioning workflows.
- Version control and governance for models
- Data archiving and version control
- Monitoring the model and its drift
- To measure and enhance services, create and use benchmarks, metrics, and monitoring.
- Providing best practices and performing proofs of concept for automated and efficient model operations at scale.
- Developing and maintaining scalable MLOps frameworks for client-specific models.
- As the sales team’s MLOps expert, I provide technical design solutions to support RFPs.
- From the outset of the project, MLOps Engineers collaborate closely with Data Scientists and Data Engineers in the Data Science Team.
Next Steps for the MLOps Engineer
While most data enthusiasts are entirely focused on honing their machine learning and data science skills, becoming a data scientist isn’t the only job path available in the field.
MLOps is quickly expanding, with the market for MLOps solutions expected to reach $4 billion by 2025.
In addition, the MLOps area offers a wide range of job prospects, as firms are currently short on workers with the combined competence of data scientists and DevOps engineers.
If you’re considering a career change and are assessing your alternatives, MLOps may be a good fit for you because it’s a relatively untapped profession with a lot of room for advancement.
Conclusion
In this blog, we have discussed Machine Learning, its importance, different types of machine learning, Machine Learning-Based Applications, Machine Learning Life Cycle, What is MLOps, its features, the need for MLOps, Best Practices of MLOps, Prerequisites of becoming an MLOps Engineer, Evolution of MLOps, Continuous X, ML Workflow, DevOps VS MLOps, some good MLOps tools, What is an MLOps Engineer, End-to-end MLOps Solution, How to implement MLOps, Hybrid MLOps Infrastructure, Scenarios that must be changed, etc. We will come up with more such use cases in our upcoming blogs. Stay tuned to keep getting all updates about our upcoming new blogs on different technologies.
Meanwhile…
Keep Exploring -> Keep Learning -> Keep Mastering
This blog is part of our effort toward building a knowledgeable and kick-ass tech community. At Workfall, we strive to provide the best tech and pay opportunities to AWS-certified talents. If you’re looking to work with global clients, and build kick-ass products while making big bucks doing so, give it a shot at workfall.com/partner today.
Frequently Asked Questions:
- Q. What is the role of an MLOps engineer?
Reading Time: 17 minutes An MLOps engineer bridges the gap between data science and operations — automating model deployment, monitoring, and CI/CD pipelines for ML systems.
- Q. What skills are essential for MLOps?
Reading Time: 17 minutes Key skills include Python, Docker, Kubernetes, CI/CD (Jenkins/GitHub Actions), cloud platforms (AWS/GCP/Azure), and monitoring tools like Prometheus or MLflow.
- Q. How does MLOps differ from traditional DevOps?
Reading Time: 17 minutes While DevOps focuses on software deployment automation, MLOps adds data versioning, model lifecycle management, and experiment tracking.
- Q. Which tools are commonly used in MLOps pipelines?
Reading Time: 17 minutes Tools include Airflow, Kubeflow, DVC, MLflow, TensorFlow Extended (TFX), and AWS SageMaker.
- Q. How can one start a career in MLOps?
Reading Time: 17 minutes Begin by learning ML fundamentals, mastering DevOps concepts, then build small end-to-end ML projects with automation and monitoring capabilities.