
Data has become such a crucial asset to businesses in today’s environment. Almost every significant company has created a data warehouse for reporting and analytics.
Utilizing information from a range of sources most data warehousing systems are difficult to set up, cost millions of dollars in initial software and hardware costs, and take months to complete. There are numerous hurdles to overcome while transitioning from traditional systems to warehouses. In this blog, we’ll provide you with the information you need to take advantage of the data warehousing industry’s strategic change from on-premises to the cloud.
In this blog, we will cover:
- What is a Data Warehouse?
- What is a Data Lake?
- Data warehouse vs data lake
- Data warehouse vs database
- Migrating Data warehouse to AWS
- What is Amazon Redshift?
- Amazon Redshift Data Warehouse Architecture
- When to use Amazon Redshift?
- Feature of Amazon Redshift
- Use Cases of Amazon Redshift
- Companies using Amazon Redshift
- Pricing
- Hands-on
- Conclusion
What is a Data Warehouse?

A data warehouse is a centralized collection of data that can be studied to help people make better decisions. Transactional systems, relational databases, and other sources provide data in a data warehouse.
To extract insights from their data, monitor business performance, and support decision-making, business users rely on reports, dashboards, and analytics tools. These reports, dashboards, and analytics tools are powered by data warehouses, which store data effectively to reduce data input and output (I/O) and deliver query results swiftly to hundreds or thousands of users at the same time. Data scientists, business analysts, and decision-makers use BI tools, SQL clients, and spreadsheets to access the data.
By employing BI technologies, you can execute quick analytics on enormous volumes of data using data warehouses and discover patterns hidden in your data. To do offline analytics and discover trends, data scientists query a data warehouse.
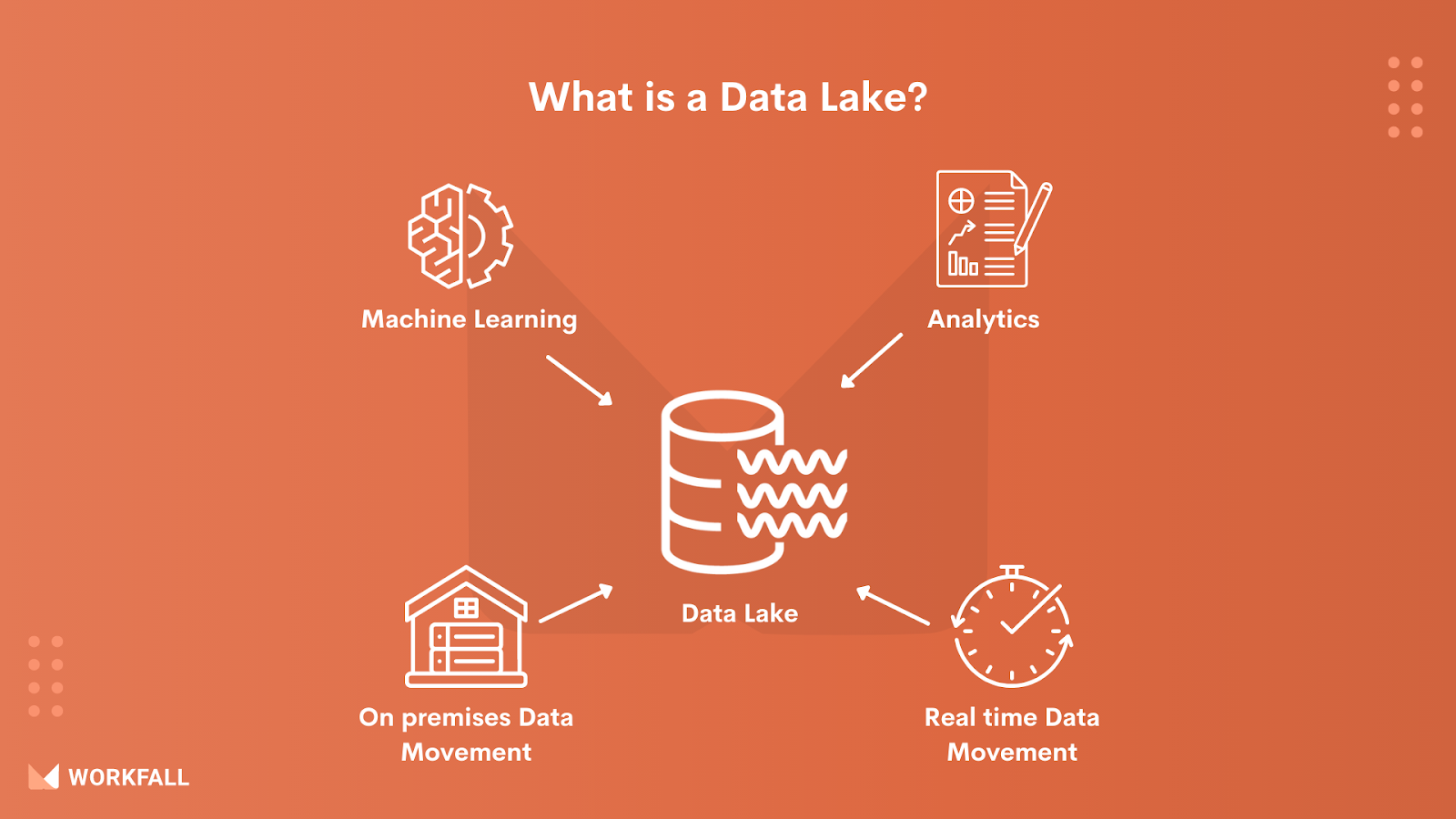
What is a Data Lake?
A data lake is a centralized repository that can hold both organized and unstructured data at any scale.
You can use dashboards and visualizations to make better decisions, and you can run several sorts of analytics—from big data processing to real-time analytics, and machine learning—without needing to first arrange the data.
Data Warehouse vs Data Lake
| Characteristics | Data Warehouse | Data Lake |
| Type of data | Transactional systems, operational databases, and line-of-business applications provide relational data. | Structured, semi-structured, and unstructured data are all considered. |
| Schema | The schema is created before the construction of the data warehouse, but can also be written during the time of analysis. | Written at the time of analysis |
| Performance | With local storage, you can get the quickest query results. | Using low-cost storage, query results are becoming faster. |
| Users | Data scientists, business analysts, and data developers. | Business analysts, data scientists, data developers, data engineers, and data architects are all professionals who work with data. |
| Use Case | Batch reporting, business intelligence, and visualizations. | Machine learning, analytics, data discovery, streaming, operational analytics, big data, and profiling. |
Data Warehouse vs Database
| Characteristics | Data Warehouse | Database |
| Suitable workloads | Big data, analytics, and reporting | Transaction Processing |
| Data source | Data was gathered and normalized from a variety of sources. | Data from a single source, such as a transactional system, is captured as-is. |
| Data capture | Bulk writing operations are often performed in batches. | To increase transaction speed, it’s been optimized for continuous write operations when new data becomes available. |
| Data normalization | Star and Snowflake schemas are examples of denormalized schemas. | Static schemas with a high level of normalization |
| Data storage | Optimized for simplicity of access and high-speed query performance using columnar storage | Optimized for high throughout write operations to a single row-oriented physical block |
Migrating Data warehouse to AWS

You can extract data from your on-premises data warehouse and move it to Amazon Redshift using an AWS SCT agent. The agent extracts your data and transfers it to Amazon S3 or an AWS Snowball Edge device for large-scale migrations. The data can then be copied to Amazon Redshift using AWS SCT.
You upload the file you want to store to an Amazon S3 bucket to store an object in Amazon S3. You can establish permissions on the object as well as any information when you upload a file.
Large-scale data migrations can involve hundreds of terabytes of data and are hampered by network speed and the sheer volume of data to be transported. AWS Snowball Edge is an AWS service that allows you to use an AWS-owned device to transport data to the cloud at faster-than-network speeds. Up to 100 TB of data can be stored on an AWS Snowball Edge device. To maintain data security and a full chain of custody, it employs 256-bit encryption and an industry-standard Trusted Platform Module (TPM). AWS Snowball Edge devices are compatible with AWS SCT.
You transfer your data in two steps when you utilize AWS SCT and an AWS Snowball Edge device. You process the data locally using the AWS SCT before moving it to the AWS Snowball Edge device. The device is then sent to AWS via the AWS Snowball Edge mechanism, and the data is automatically loaded into an Amazon S3 bucket by AWS. After that, you utilize AWS SCT to migrate the data to Amazon Redshift once the data is accessible on Amazon S3. While AWS SCT is closed, data extraction agents can function in the background.
What is Amazon Redshift?
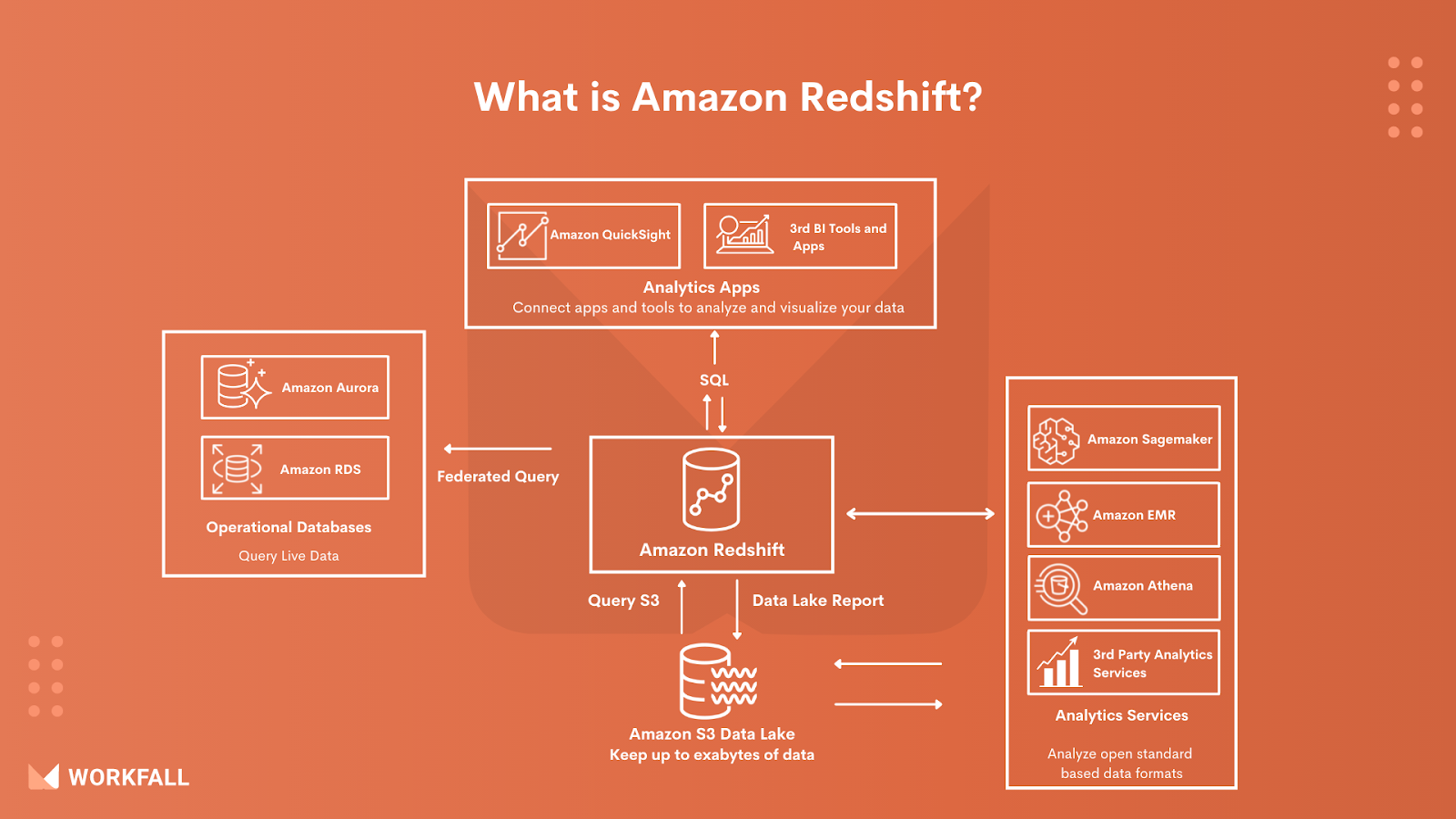
Amazon Redshift is a fully managed large-scale data warehouse that Amazon offers as a cloud service. In this context, completely managed means that the end-user is relieved of all responsibilities for hosting, maintaining, and ensuring the availability of an always-on data warehouse. It has a querying layer that is compatible with Postgres and is compatible with most SQL-based tools and data intelligence applications.
Redshift allows you to utilize conventional SQL to query and aggregate exabytes of structured and semi-structured data from your data warehouse, operational database, and data lake.
Redshift makes it simple to save the results of your queries to your S3 data lake in open formats like Apache Parquet, so you can use other analytics services like Amazon EMR, Amazon Athena, and Amazon SageMaker to do more analysis.
Amazon Redshift Data Warehouse Architecture
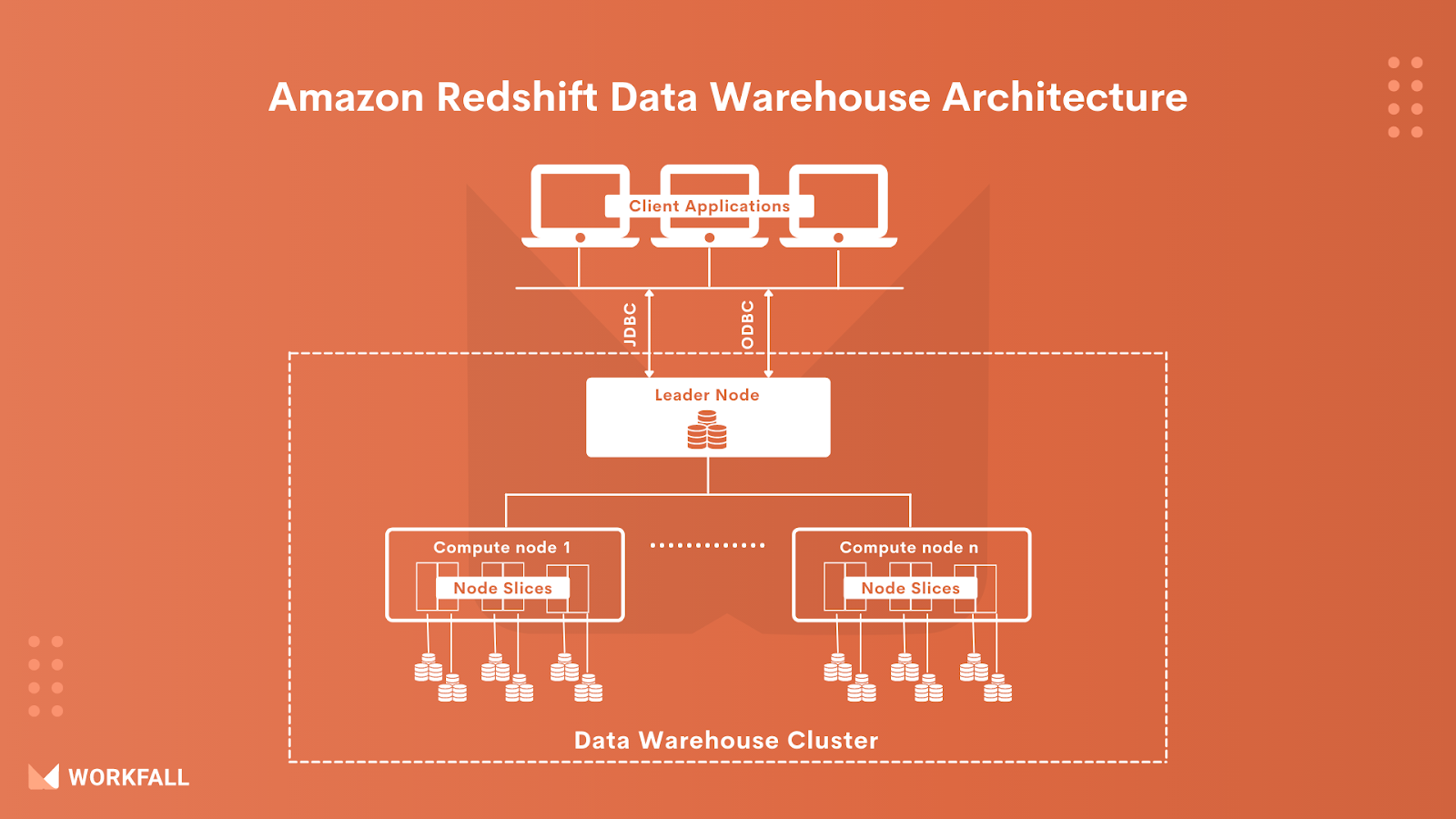
Redshift Cluster: The basic infrastructure component of Redshift is a cluster of nodes. One leader node and a number of compute nodes are typical components of a cluster. There is no additional leader node in circumstances where only one computes node is present.
Compute Nodes: Each computing node is equipped with its own CPU, memory, and storage disc. Client applications are unaware of compute nodes’ existence and never interact with them directly.
Leader Node: The leader node is in charge of all communications with the client apps. The leader node is also in charge of compute node coordination. The leader node is also in charge of query parsing and execution plan development. When the leader node receives a query, it constructs an execution plan and distributes the produced code to the compute nodes. Each compute node is given a piece of the data. The leader node is in charge of aggregating the results in the end.
Users can choose between two types of nodes in Redshift: Dense Storage nodes and Dense Compute nodes. Customers can choose them based on the nature of their needs, whether they are storage- or compute-intensive. The number of nodes in Redshift’s cluster can be increased, or individual node capacity can be increased, or both.
Internally, the compute nodes are divided into slices, each of which is assigned a fraction of the CPU and memory. The node slices will work in parallel to finish the work that the leader node has assigned.
When to use Amazon Redshift?
Many Amazon services are used in your ETL design, and you expect to employ many more Amazon services in the future. Redshift is the clear winner here, thanks to its strong connectivity with other Amazon services.
Your cluster will constantly be near-maximum capacity, with query demands distributed over time and little idle time.
You have great faith in your product and expect a cluster to be fully operational for at least a year. This enables you to take advantage of AWS Reserved pricing, which can help you save a lot of money.
The data design is totally organized, and there are no plans to store semi-structured or unstructured data in the warehouse in the future.
Complete security and compliance are required from the start, and there is no way to cut corners on security in order to save money.
Features of Amazon Redshift
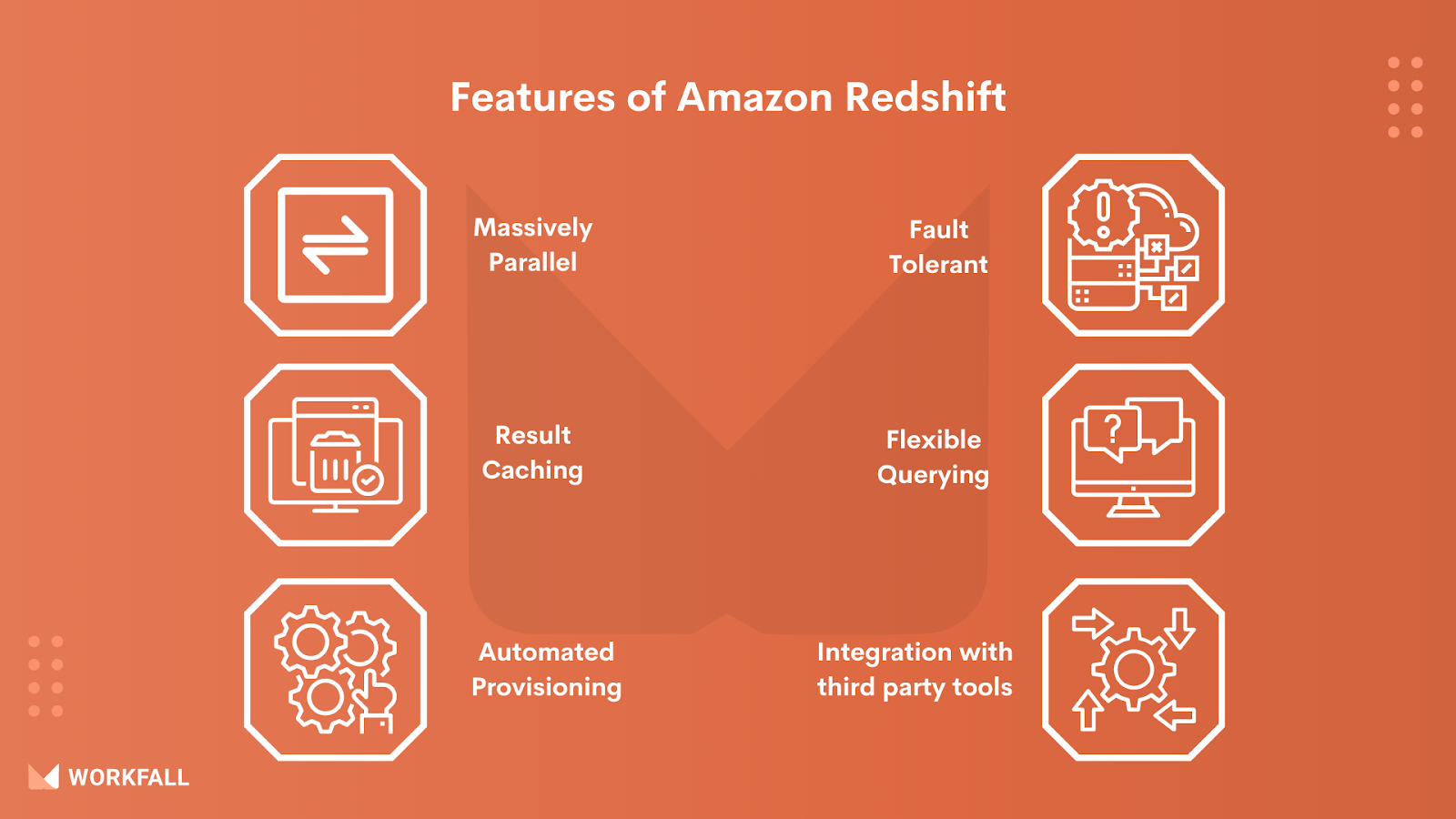
Massively Parallel: On datasets ranging in size from gigabytes to exabytes, Amazon Redshift provides lightning-fast query performance. To reduce the amount of I/O required for queries, Redshift employs columnar storage, data compression, and zone maps. To take advantage of all available resources, it leverages massively parallel processing (MPP) data warehouse architecture to parallelize and distribute SQL operations.
Result Caching: For recurring queries, Amazon Redshift leverages result caching to offer sub-second response times. When a query is made, Redshift checks the cache to determine whether there is a previously cached response. Instead of re-running the query, if a cached result is available and the data has not changed, the cached result is returned instantly.
Automated Provisioning: With a few clicks on the AWS Management Console, you can create a new data warehouse, and Redshift will take care of the infrastructure. Most administrative duties, such as backups and replication, are automated, allowing you to focus on your data rather than the administration.
Fault Tolerant: Amazon Redshift includes a number of capabilities that help your data warehouse cluster be more reliable. For fault tolerance, Redshift continuously monitors the cluster’s health and automatically re-replicates data from failed discs and replaces nodes as needed.
Integration with third-party tools: Working with industry-leading tools and professionals for loading, manipulating, and visualizing data will improve Amazon Redshift.
Flexible Querying: Amazon Redshift allows you to run queries directly from the console or connect your favorite SQL client tools, libraries, or business intelligence tools. The AWS console’s Query Editor offers a comprehensive interface for running SQL queries on Redshift clusters and visualizing the results.
Use Cases of Amazon Redshift
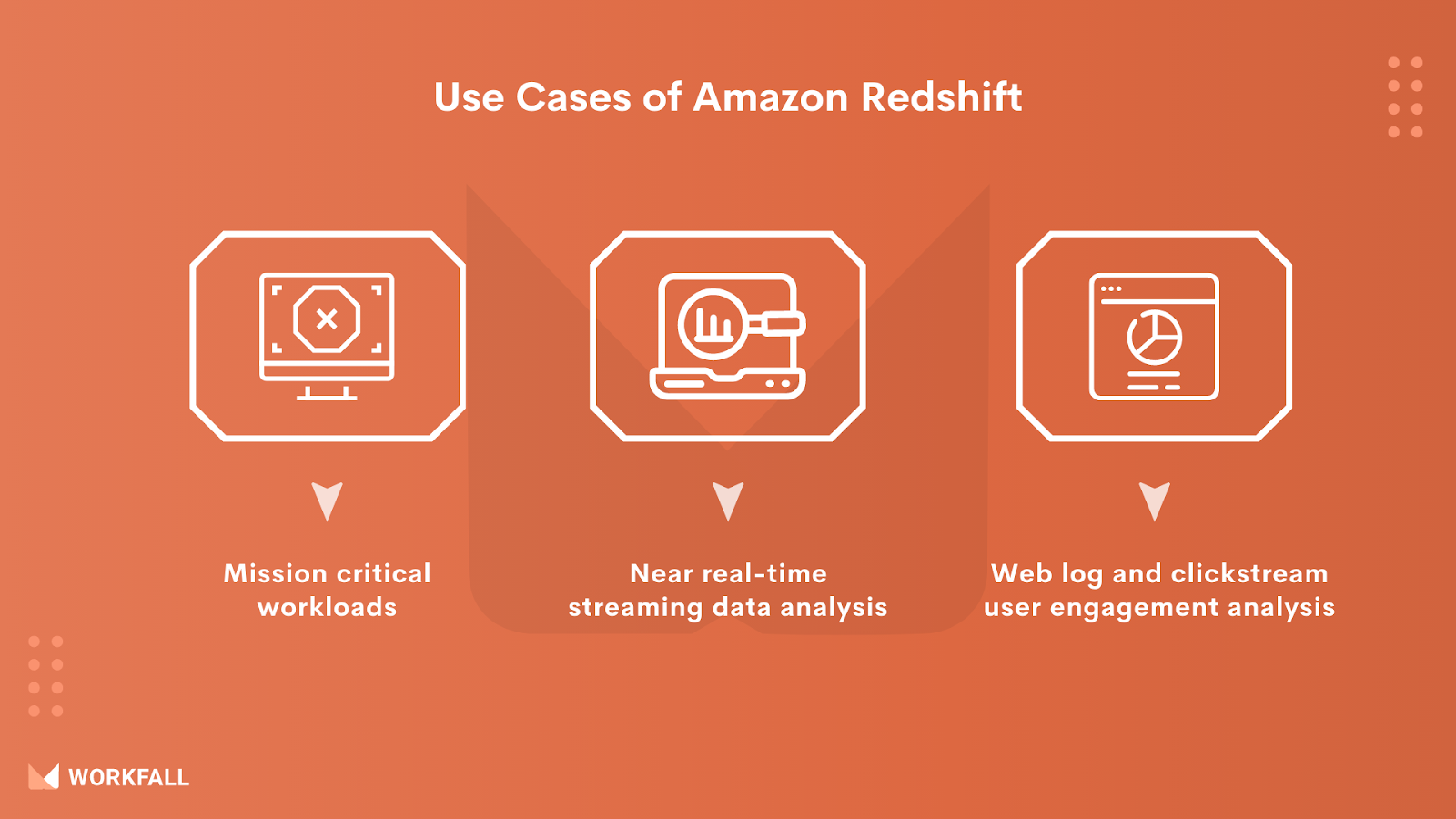
Mission-critical workloads: As previously stated, Redshift’s Concurrency Scaling feature makes it completely scalable, and its built-in fault tolerance allows it to be used for mission-critical workloads.
Near real-time streaming data analysis: Redshift’s performance capabilities make it an ideal component of a system that necessitates real-time analytics of enormous amounts of streaming data. For example, gaining insights from a worldwide, enterprise-wide network of IoT devices. Here’s an example of how to do it with Heroku in practice.
Weblog and clickstream user engagement analysis: Users’ interactions with websites and online and mobile apps generate a tremendous amount of data for tech-first businesses. To uncover previously undisclosed user interaction insights, combine both old and incoming data using Redshift as part of an analysis stack.
Companies using Amazon Redshift

Pricing
You can pay for capacity by the hour using Amazon Redshift on-demand pricing, with no obligations or upfront charges; you simply pay an hourly amount based on the type and number of nodes in your cluster. Following a billable status change such as creating, deleting, pausing, or resuming the cluster, partial hours are invoiced in one-second increments. You can suspend on-demand charging while the cluster is paused using the pause and resume feature. You only have to pay for backup storage while a cluster is halted. This frees you from having to plan and buy data warehouse capacity ahead of time, and it allows you to manage environments for development and testing more cost-effectively.

Hands-on
Today we will see how to create a Redshift cluster and load data from S3 to Redshift. Then perform S3 queries on that data.
Steps include :
- Create an IAM role for the cluster
- Create redshift cluster
- Import sample data into S3
- Create tables as per the defined schema in Redshift query editor
- Use copy command to import s3 data into Redshift table created
- Run SQL queries to extract data.
Go to AWS Console -IAM -Select Redshift
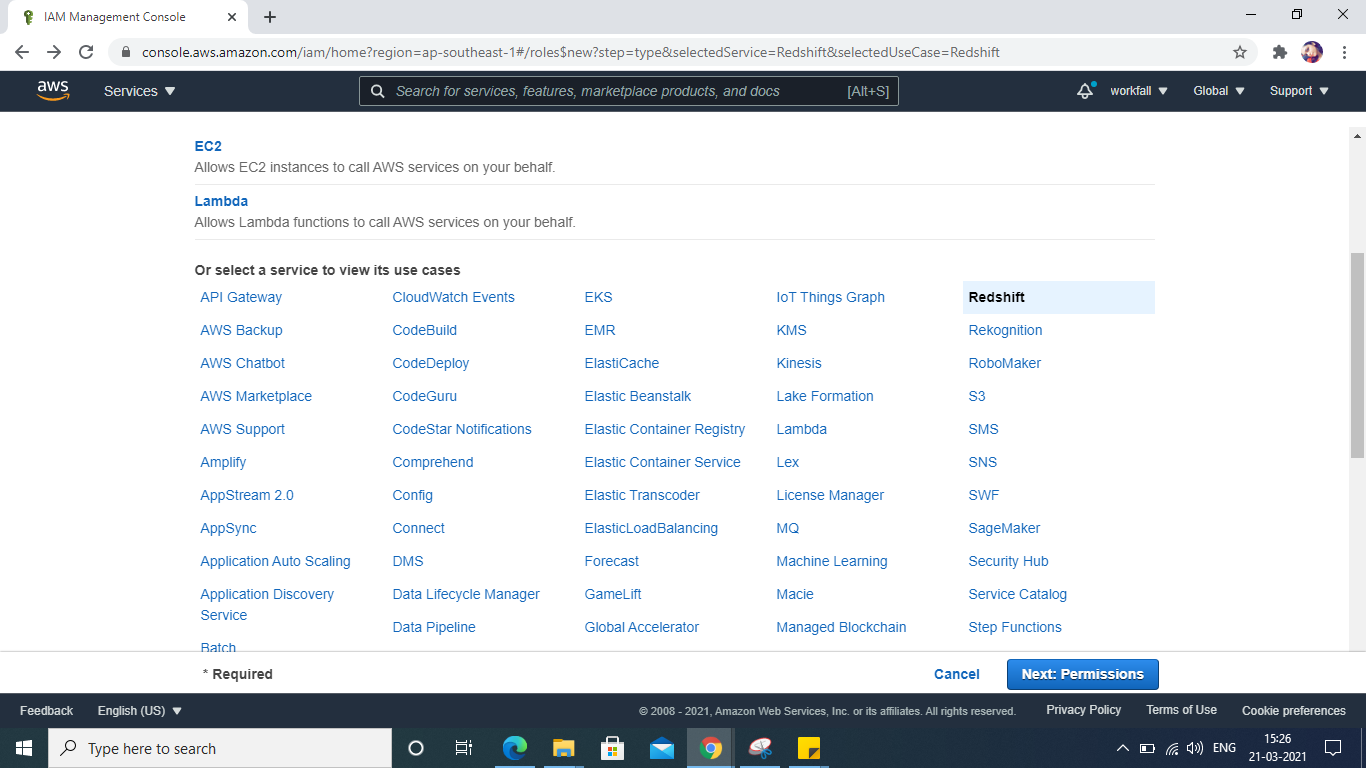
Click Redshift – Customizable
Click Next: Permissions

Enter “AmazonFullAccess” into the Search field
Select the checkbox.
Click Next: Tags.
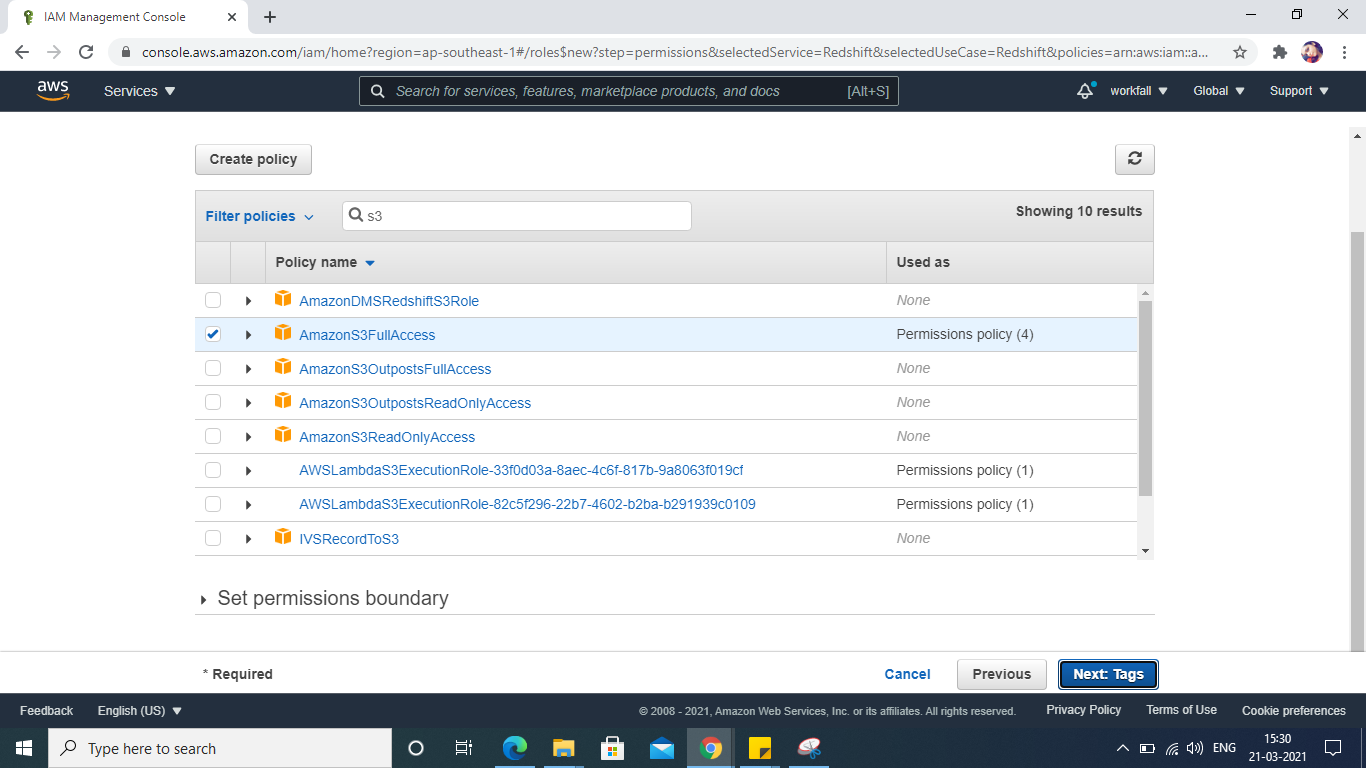
Name your IAM role:
Enter the desired name for the role. (this is a required field).
Click Create Role.
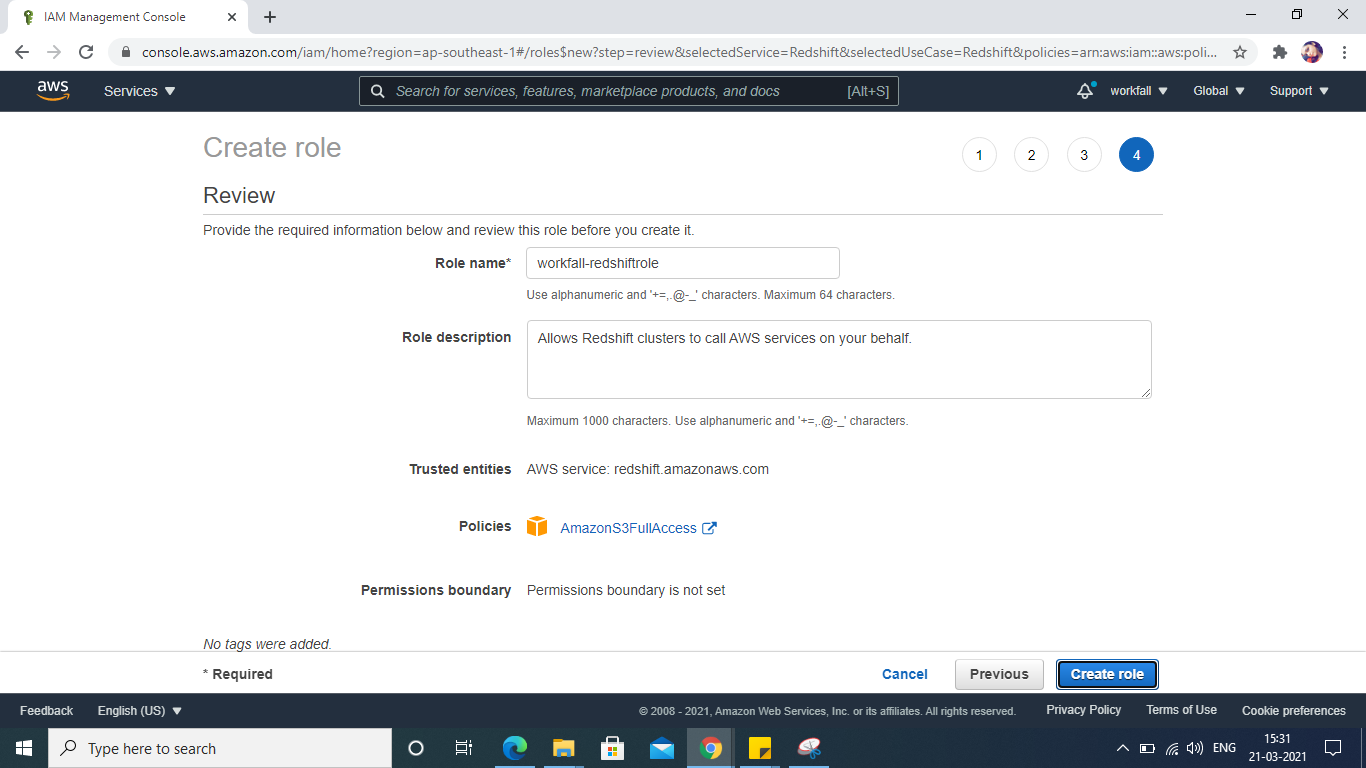
Create Redshift Cluster
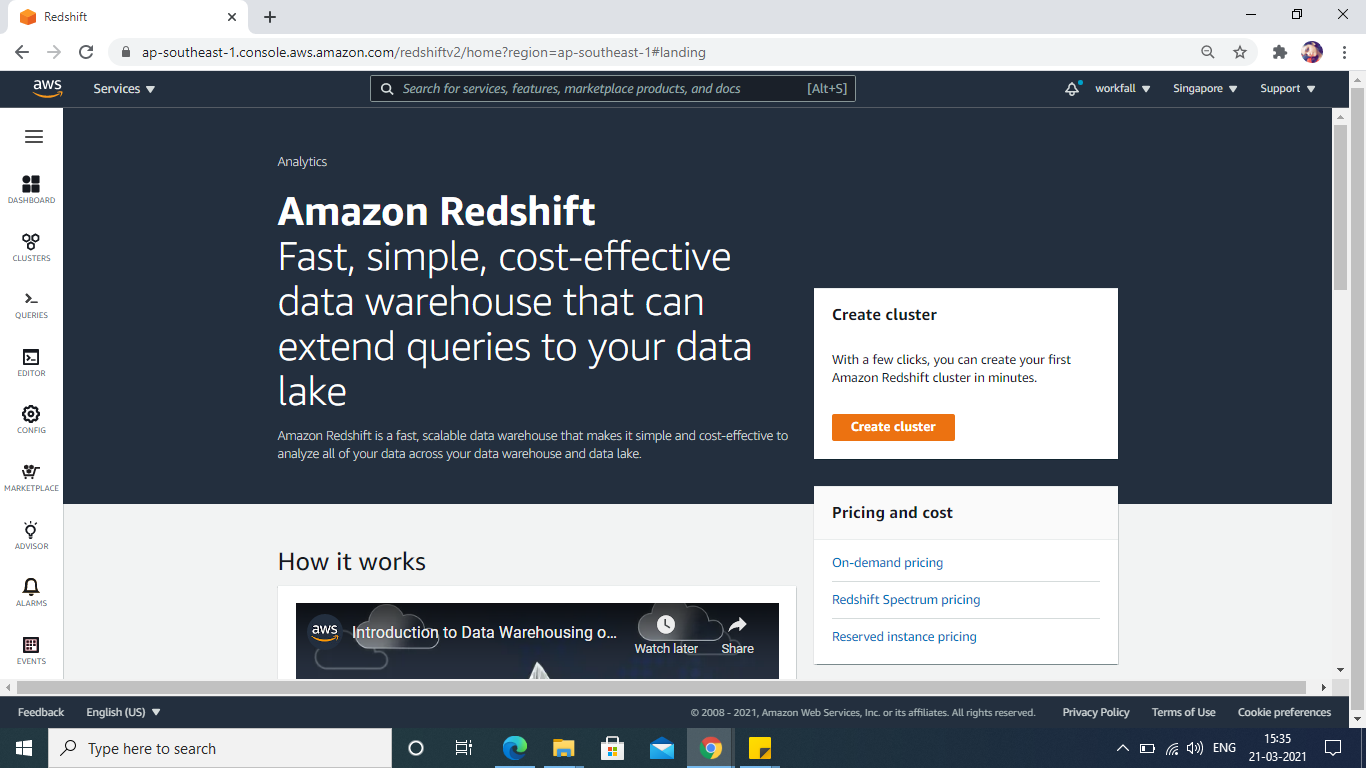
Name the cluster, select free trial for use

Choose a password for your cluster.

Select your newly generated IAM role from the drop-down named Available IAM Roles to attach it to the cluster.
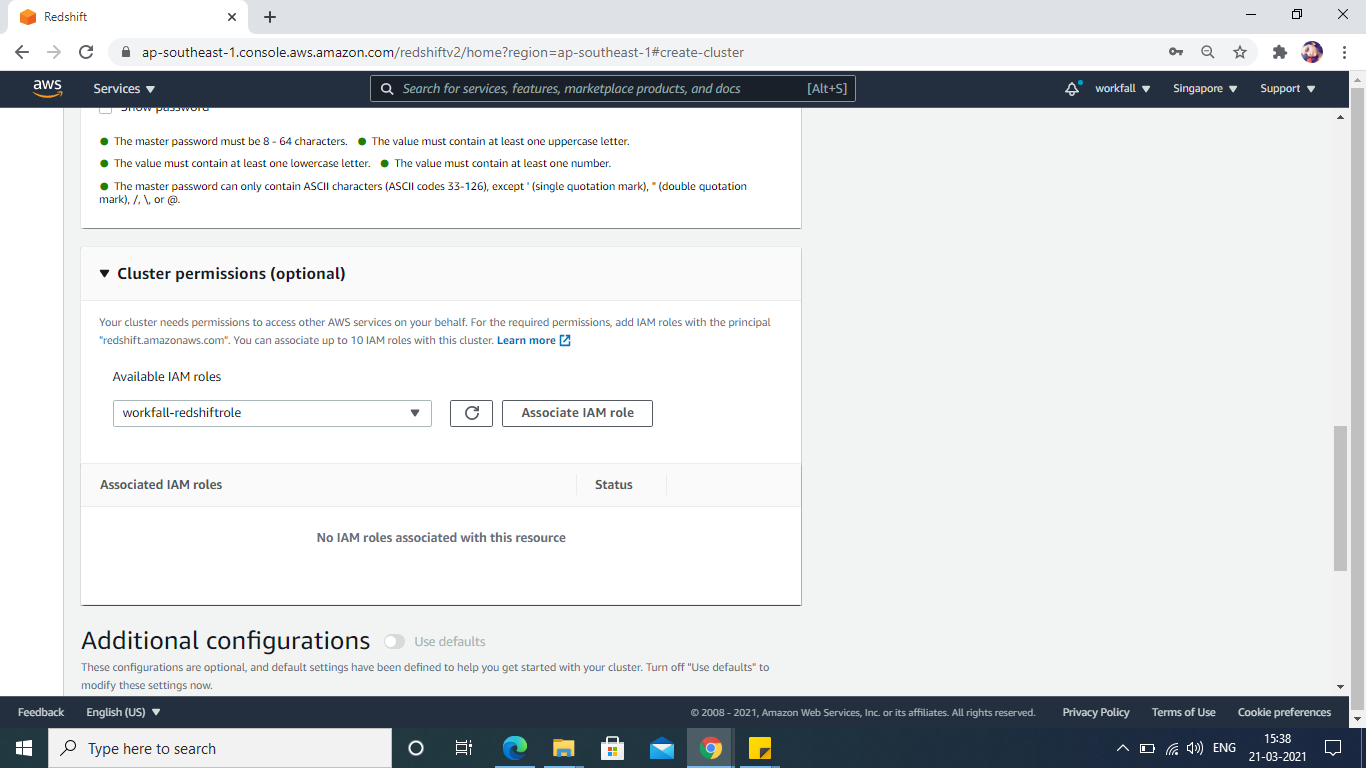
Launch the cluster.

This is how you can see, once the cluster is available after launch.
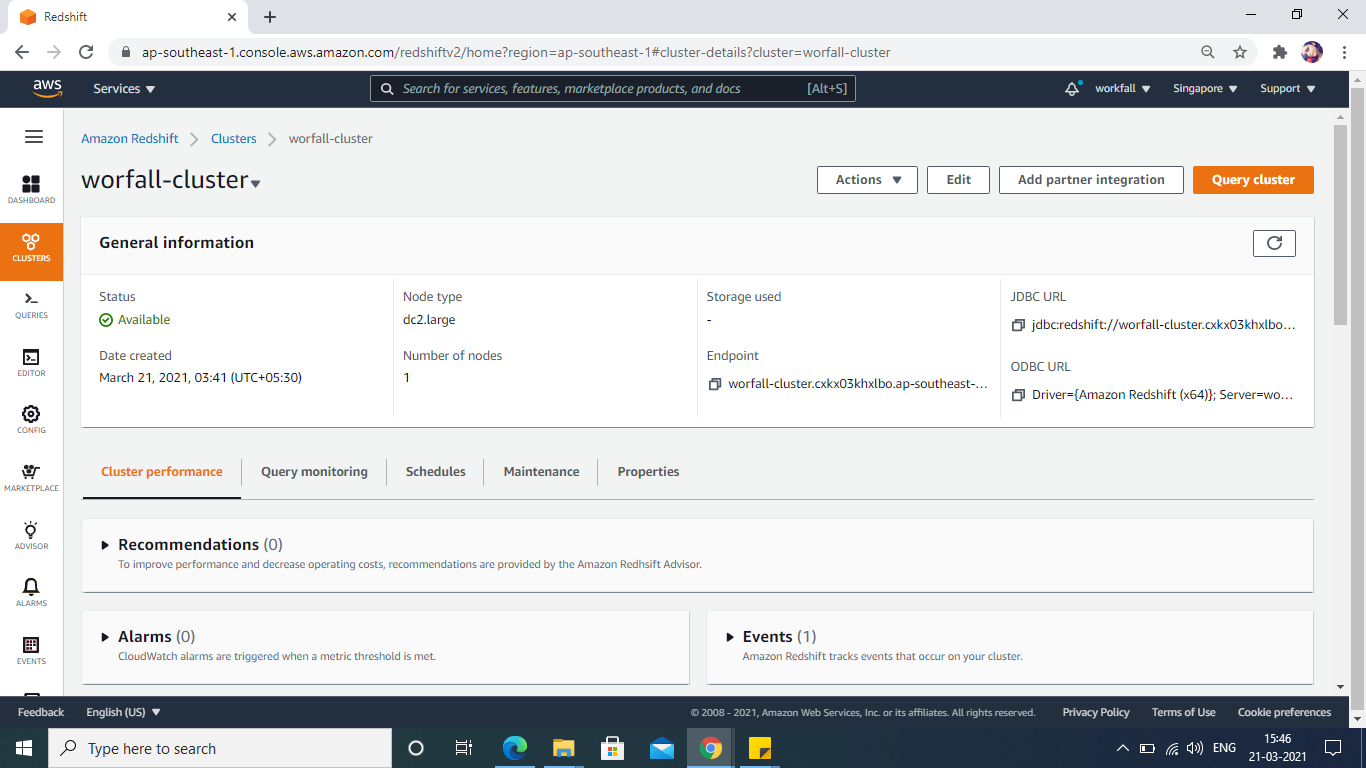
Loading data into Redshift
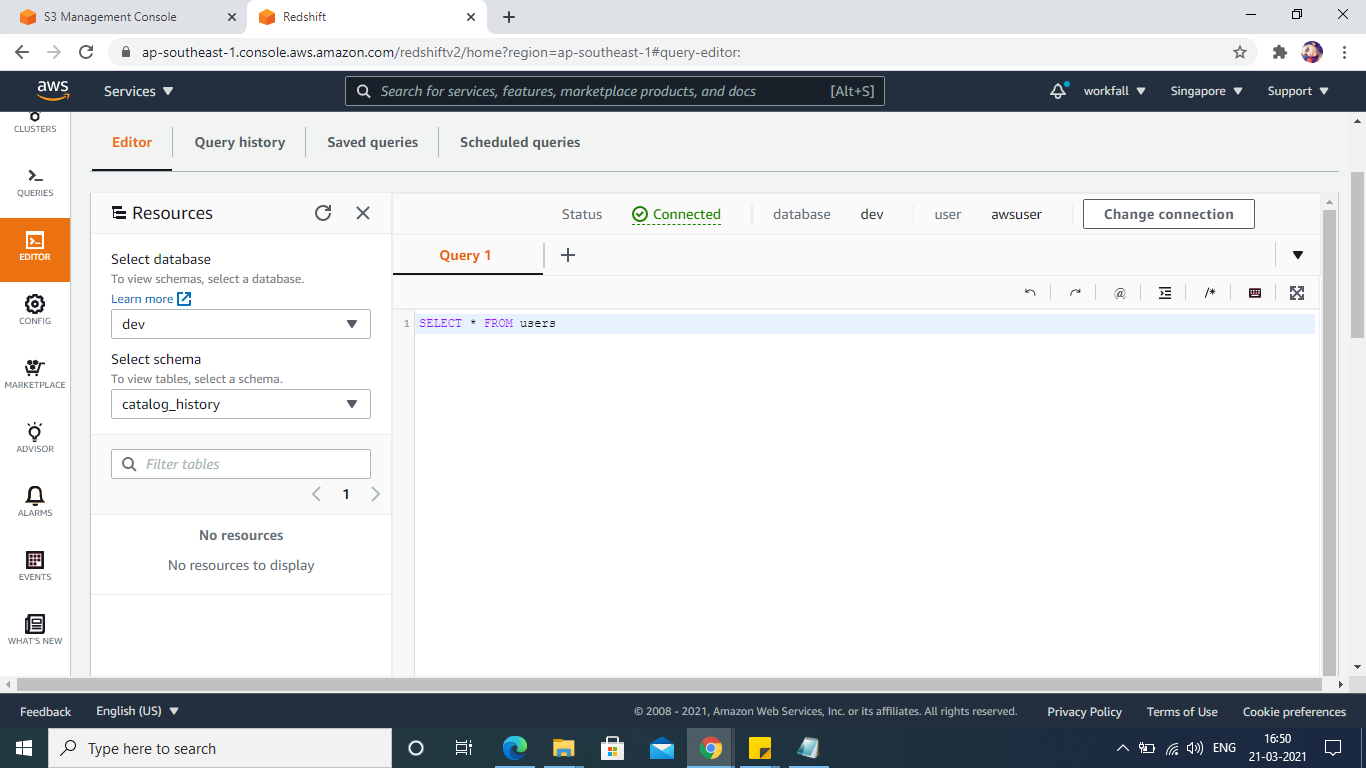
Go to the Redshift Query editor, and connect using the credentials created earlier.
Click on Connect.
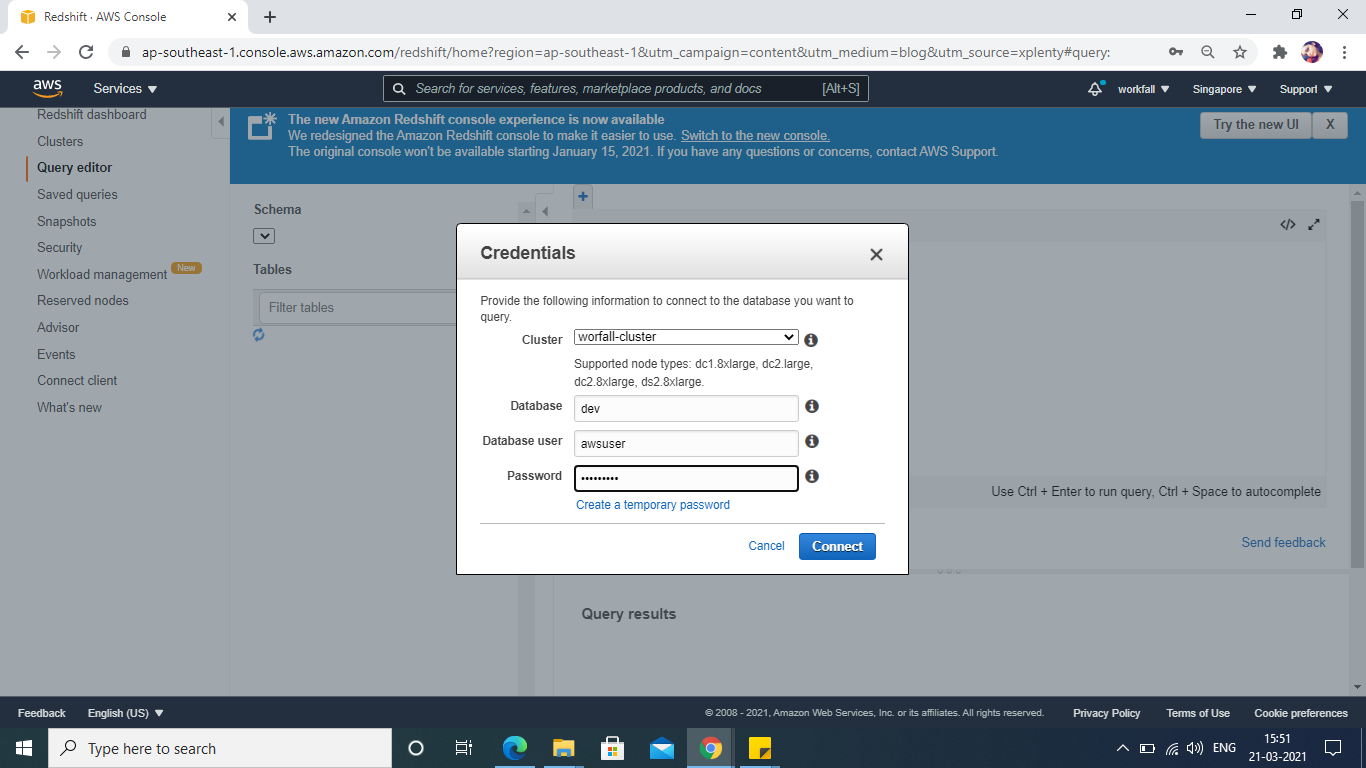
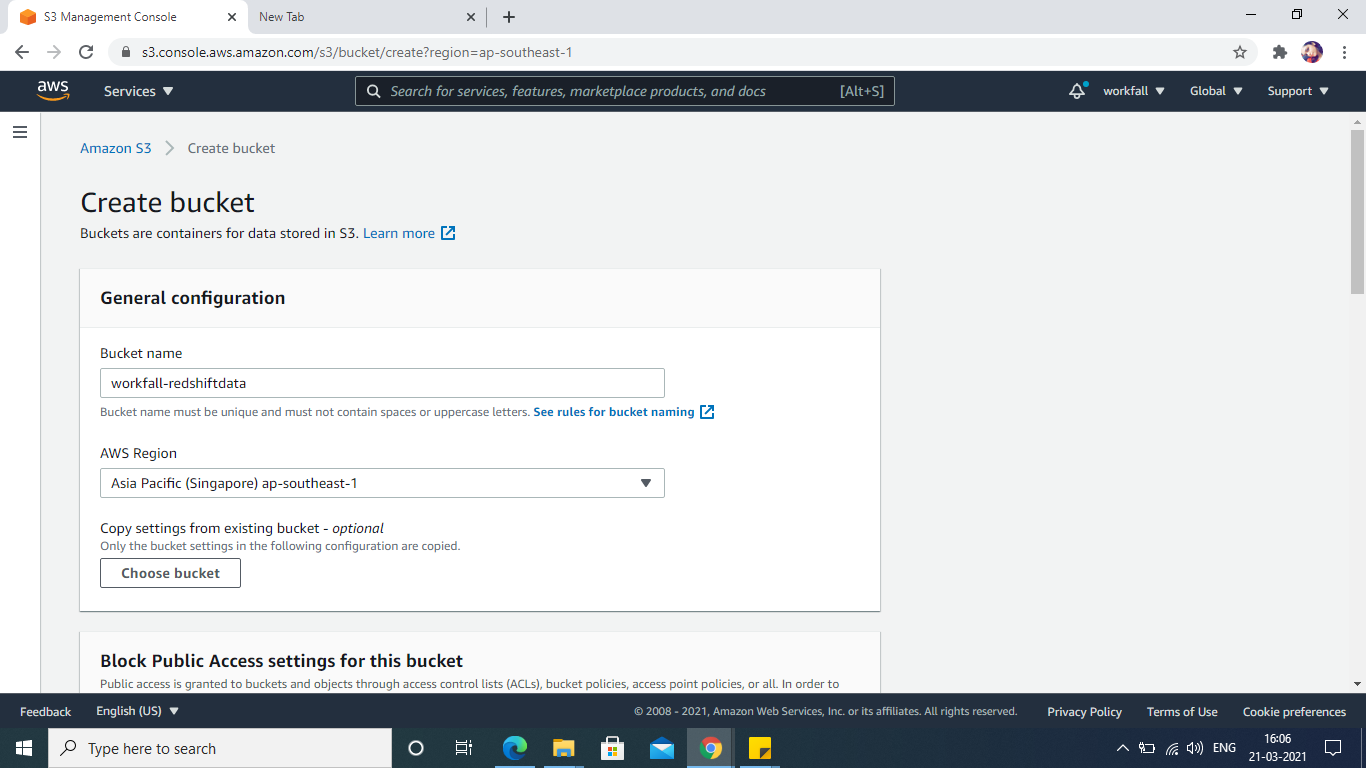
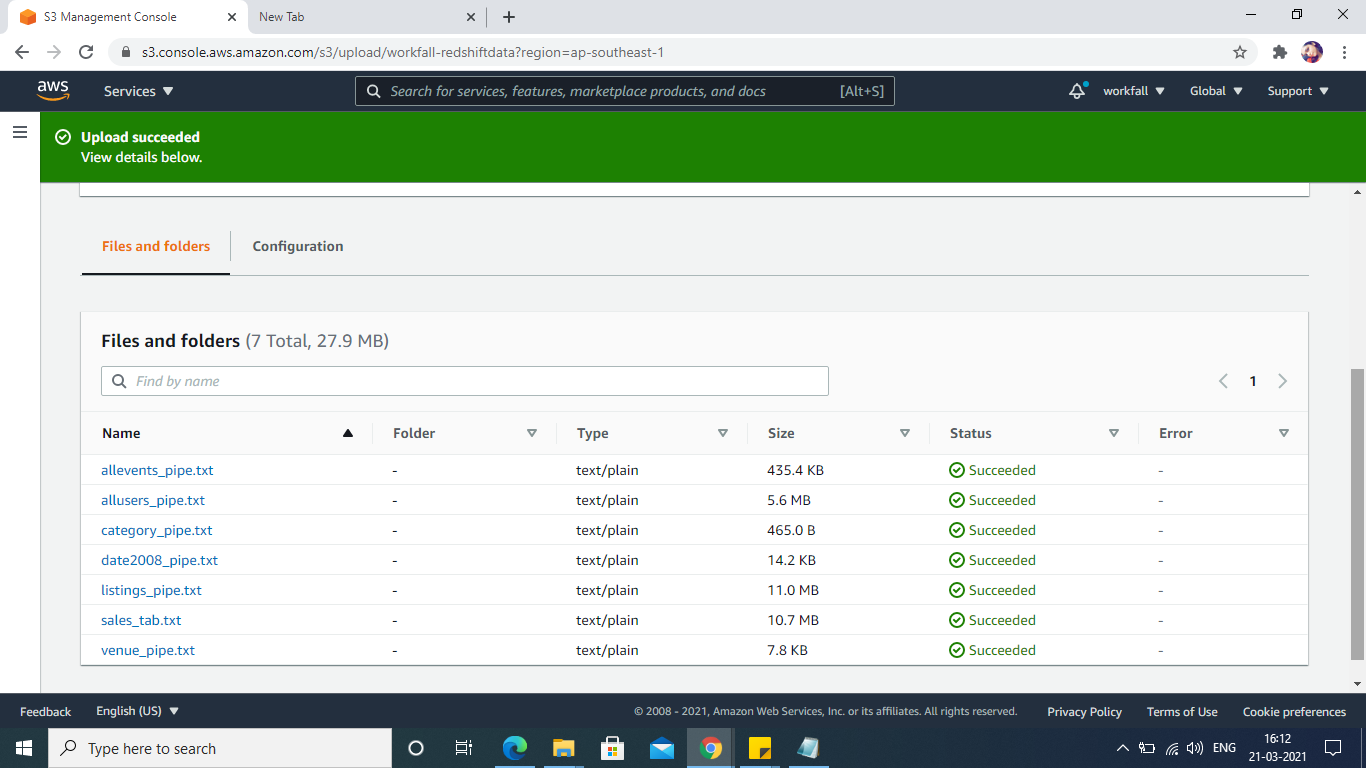
In order to import data from S3, we first will create an S3 bucket and load the sample files into it.
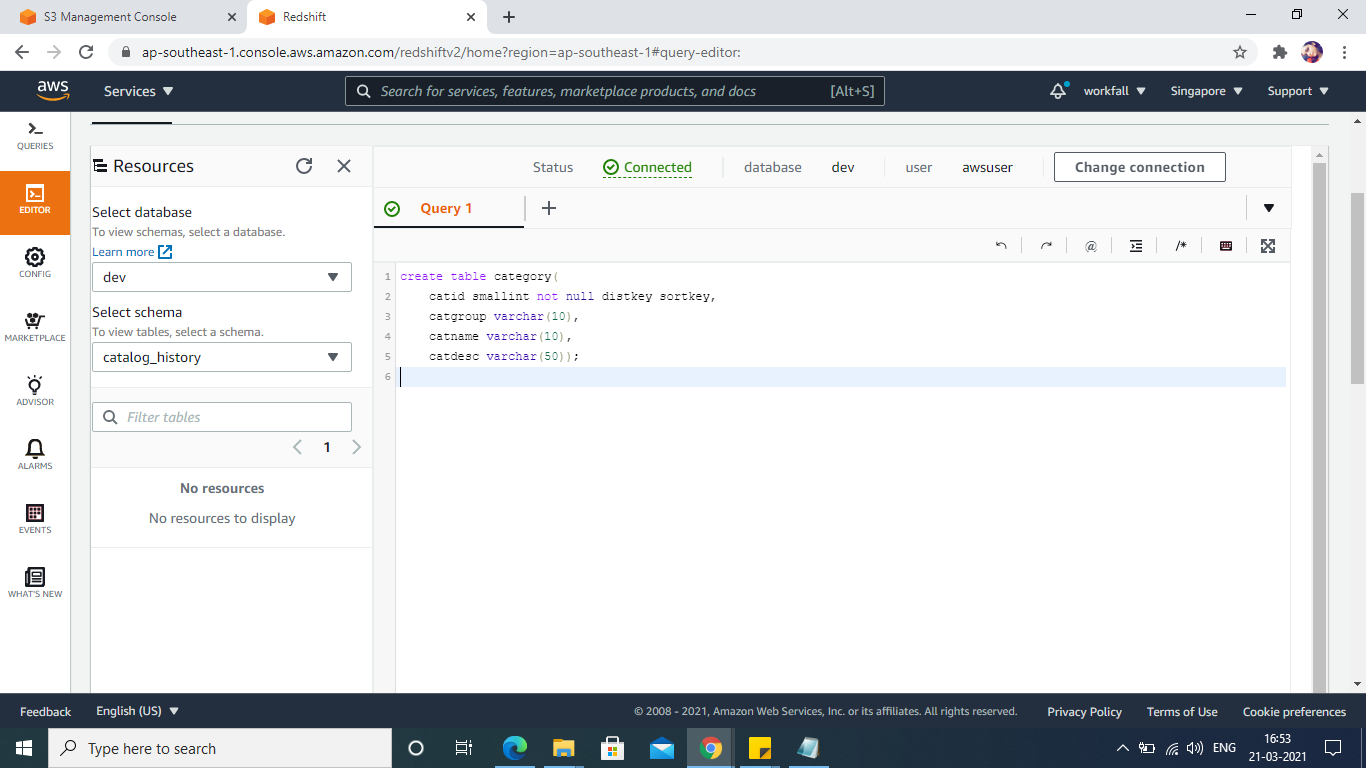
Create the table as per schema, here we are creating users and category table.

Now you’ll connect the tables to the information in the Sample S3 Buckets, run the below commands to copy data from the bucket, and load it into Redshift.

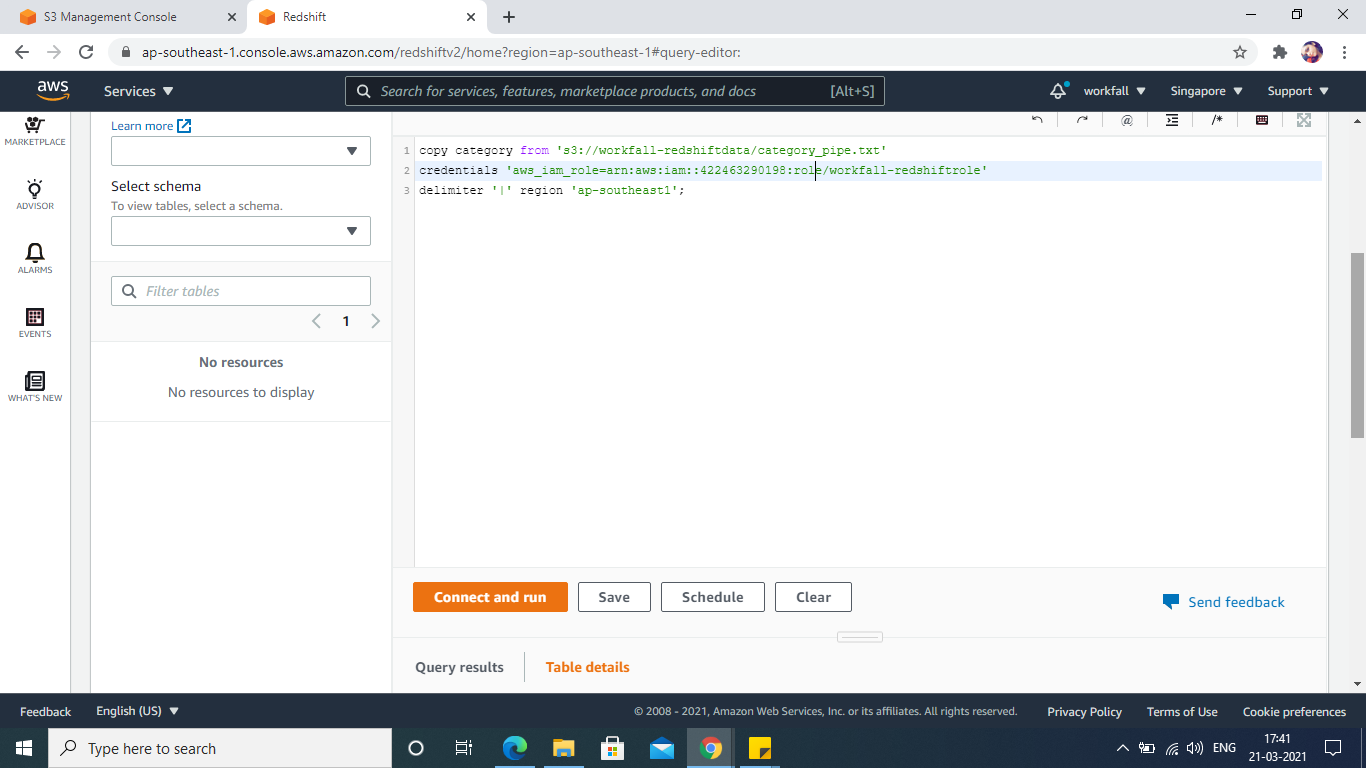
Once the data is loaded, we can execute SQL queries against the data.


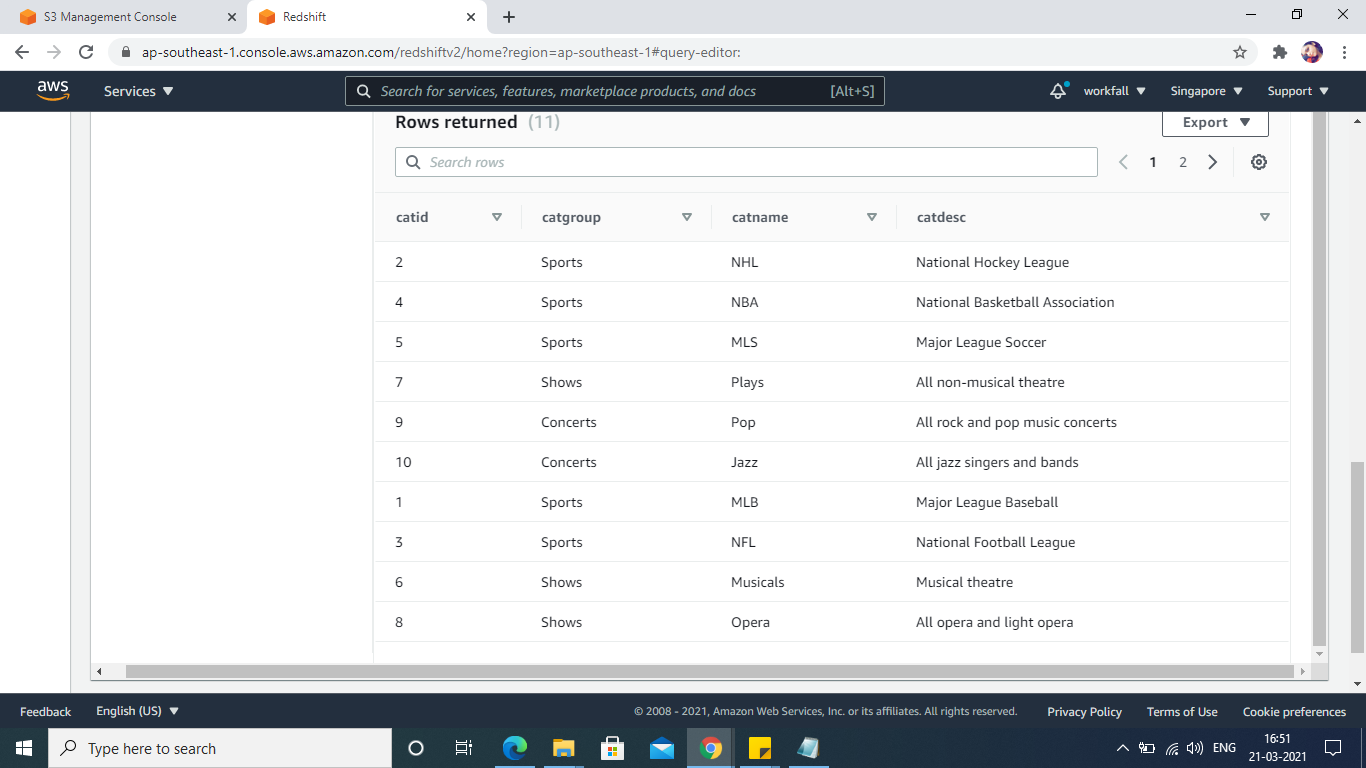
Similar results can be obtained by loading the other tables also and performing SQL queries on them as well.
Conclusion
In this blog, we had a look at the Data Warehouse, its benefits, also the difference between data lakes, databases, and data warehouses. did a deep dive into AWS Redshift, how it works, its major benefits, and use cases, and also in the hands-on, we saw how to load data into Redshift from S3 and perform SQL operations on it. We will have a look at other data warehouses and analytics services provided by AWS in our upcoming blogs. Stay tuned to keep getting all updates about our upcoming new blogs on AWS and relevant technologies.
Meanwhile …
Keep Exploring -> Keep Learning -> Keep Mastering
This blog is part of our effort toward building a knowledgeable and kick-ass tech community. At Workfall, we strive to provide the best tech and pay opportunities to AWS-certified talents. If you’re looking to work with global clients, and build kick-ass products while making big bucks doing so, give it a shot at workfall.com/partner today.


