
How to easily analyze data and run different queries using Amazon Redshift Serverless without having to manage the infrastructure?
Reading Time: 9 minutes To know about what’s new in Amazon Redshift Serverless, refer to Part 1 of the blog here: What’s new in Amazon Redshift – Serverless? Hands-on In this hands-on, we will see how we can analyze data and run the different queries using Amazon Redshift Serverless without the need of managing the infrastructure using the Serverless […]

What’s new in Amazon Redshift – Serverless?
Reading Time: 6 minutes Amazon Redshift has added a slew of new features in recent months, including a game-changing one – SERVERLESS 🚀 AWS introduced the preview of Amazon Redshift Serverless last year at re:Invent 2021, a serverless option of Amazon Redshift that allows you to analyze data at any scale without having to manage data warehouse infrastructure. You […]

Create Redshift Clusters And Query Data
Reading Time: 11 minutes Data has become such a crucial asset to businesses in today’s environment. Almost every significant company has created a data warehouse for reporting and analytics. Utilizing information from a range of sources most data warehousing systems are difficult to set up, cost millions of dollars in initial software and hardware costs, and take months to […]
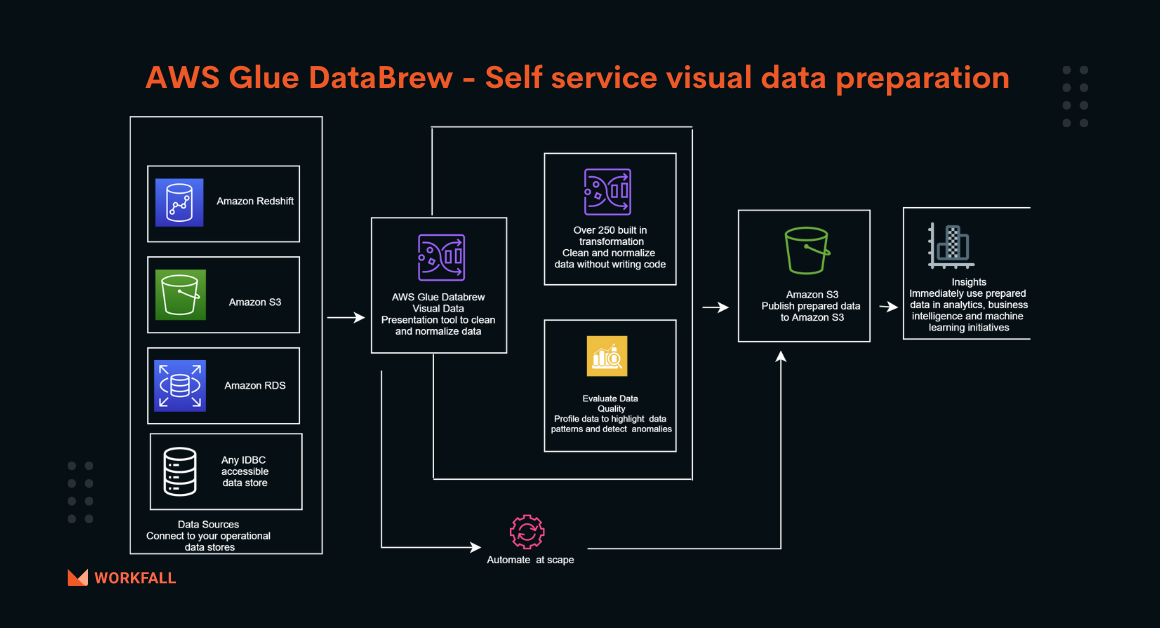
AWS Glue DataBrew — A no-code visual data preparation tool for data scientists.
Reading Time: 7 minutes AWS Glue is a serverless managed service that prepares data for analysis through automated ETL processes. This is a simple and cost-effective method for categorizing and managing big data in the enterprise. It gives businesses a data integration tool that prepares data from multiple sources and organizes it in a central repository where it can […]
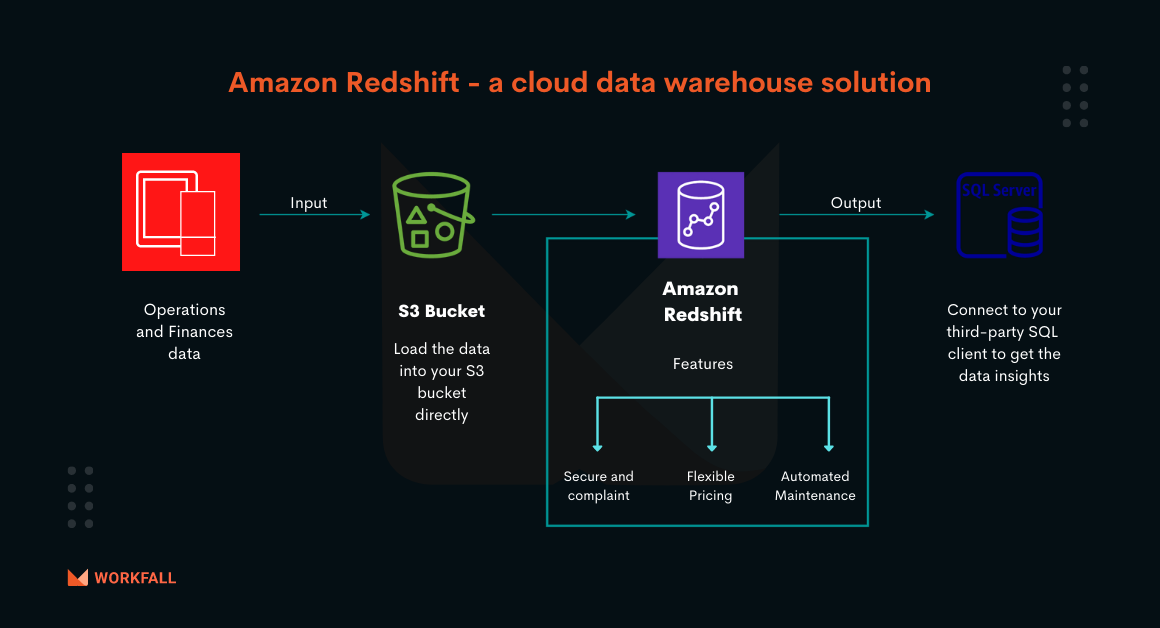
How to design a Redshift cluster and query data using a query editor?
Reading Time: 4 minutes Amazon Redshift is a cloud Data warehouse solution for querying and analyzing data. In this blog, we will discuss how Redshift delivers fast query performance. Amazon Redshift provides different types of instances to maximize speed for performance-intensive workloads. It provides fast performance for datasets varying in size from gigabytes to petabytes. It is easily scalable […]