
Have you ever wondered how huge IT companies construct their ETL pipelines for production? Are you curious about how TBs and ZBs of data are effortlessly captured and rapidly processed to a database or other storage for data scientists and analysts to use? The answer is the serverless data integration service, AWS Glue. It makes discovering, preparing, and combining data for analytics, machine learning, and app development a breeze. AWS Glue has all of the data integration features you’ll need, so you can start analyzing and using your data in minutes rather than months.
In this blog, we will cover:
- What is AWS Glue?
- Components of AWS Glue
- What is AWS Glue Data Catalog?
- How does it work?
- Benefits of AWS Glue
- Use Cases
- Features of AWS Glue
- When to use AWS Glue
- Data Sources supported by AWS Glue
- AWS Glue data pricing
- Customers using AWS Glue
- Conclusion
What is AWS Glue?
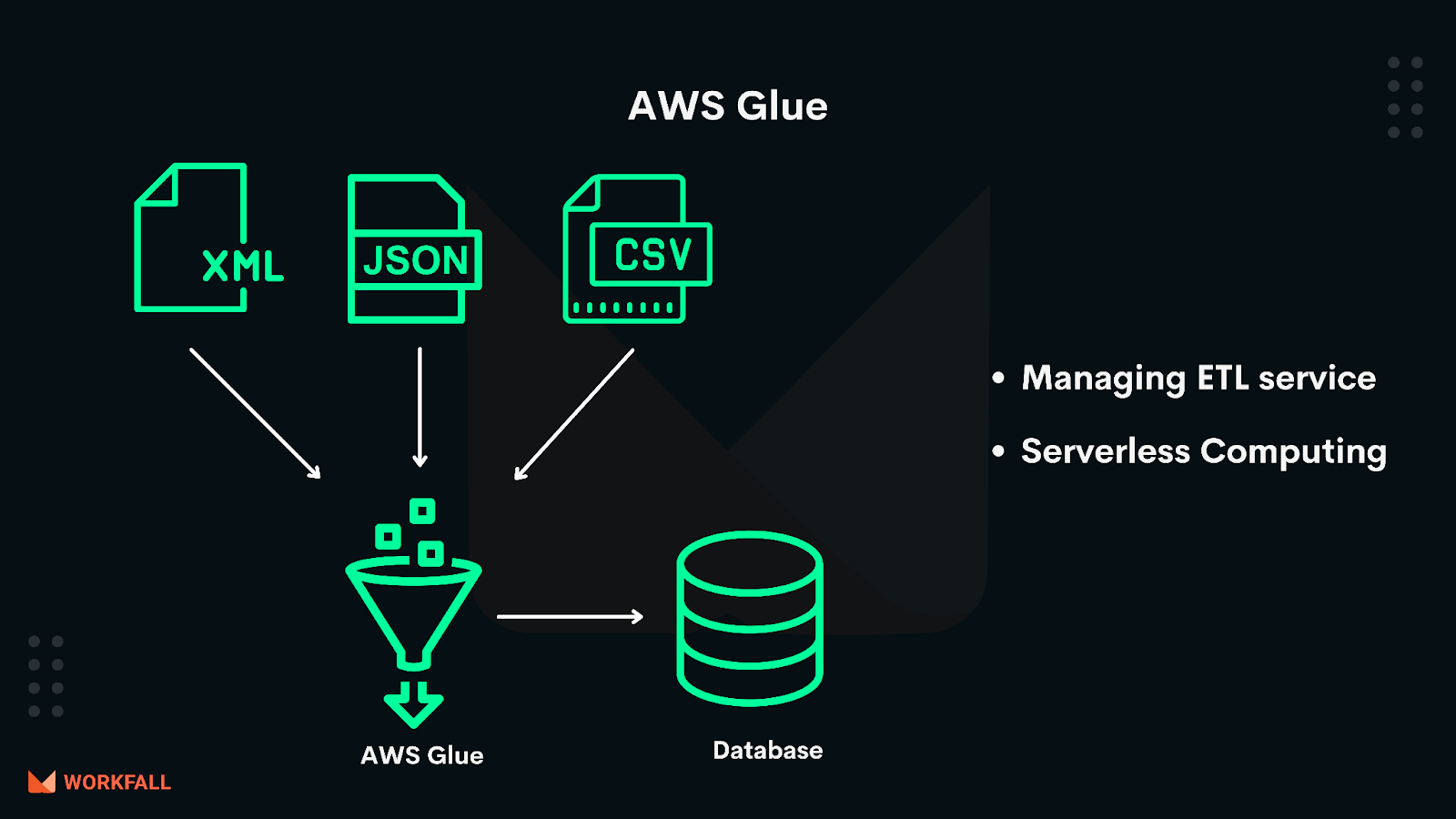
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development. AWS Glue provides all the capabilities needed for data integration, so you can start analyzing your data and putting it to use in minutes instead of months. AWS Glue provides both visual and code-based interfaces to make data integration easier. Users can easily find and access data using the AWS Glue Data Catalog.
Data engineers and ETL (extract, transform, and load) developers can visually create, run, and monitor ETL workflows with a few clicks in AWS Glue Studio. Data analysts and data scientists can use AWS Glue DataBrew to visually enrich, clean, and normalize data without writing code. With AWS Glue Elastic Views, application developers can use familiar Structured Query Language (SQL) to combine and replicate data across different data stores.
Components of AWS Glue

AWS Glue consists of a Data Catalog which is a central metadata repository; an ETL engine that can automatically generate Scala or Python code; a flexible scheduler that handles dependency resolution, job monitoring, and retries; AWS Glue DataBrew for cleaning and normalizing data with a visual interface; and AWS Glue Elastic Views, for combining and replicating data across multiple data stores. Together, these automate much of the undifferentiated heavy lifting involved with discovering, categorizing, cleaning, enriching, and moving data, so you can spend more time analyzing your data.
What is AWS Glue Data Catalog?

The AWS Glue Data Catalog is a central repository to store structural and operational metadata for all your data assets. For a given data set, you can store its table definition, and physical location, add business-relevant attributes, as well as track how this data has changed over time.
The AWS Glue Data Catalog also provides out-of-box integration with Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum. Once you add your table definitions to the Glue Data Catalog, they are available for ETL and also readily available for querying in Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum so that you can have a common view of your data between these services.
How does it work?
AWS Glue calls API operations to transform your data, create runtime logs, store your job logic, and create notifications to help you monitor your job runs. The AWS Glue console connects these services into a managed application, so you can focus on creating and monitoring your ETL work. The console performs administrative and job development operations on your behalf. You supply credentials and other properties to AWS Glue to access your data sources and write to your data targets.
Benefits of AWS Glue

- Orchestration: You don’t need to set up or maintain infrastructure for ETL task execution. Amazon takes care of all the lower-level details. AWS Glue also automates a lot of things. You can quickly determine the data schema, generate code, and start customizing it. AWS Glue simplifies logging, monitoring, alerting, and restarting in failure cases as well.
- It complements other Amazon services: So, data sources and targets such as Amazon Kinesis, Amazon Redshift, Amazon S3, and Amazon MSK are very easy to integrate with AWS Glue. Other popular data storages that can be deployed on Amazon EC2 instances are also compatible with it.
- It can be cheaper because users only pay for the consumed resources: If your ETL jobs require more computing power from time to time but generally consume fewer resources, you don’t need to pay for the peak time resources outside of this time.
Use Cases
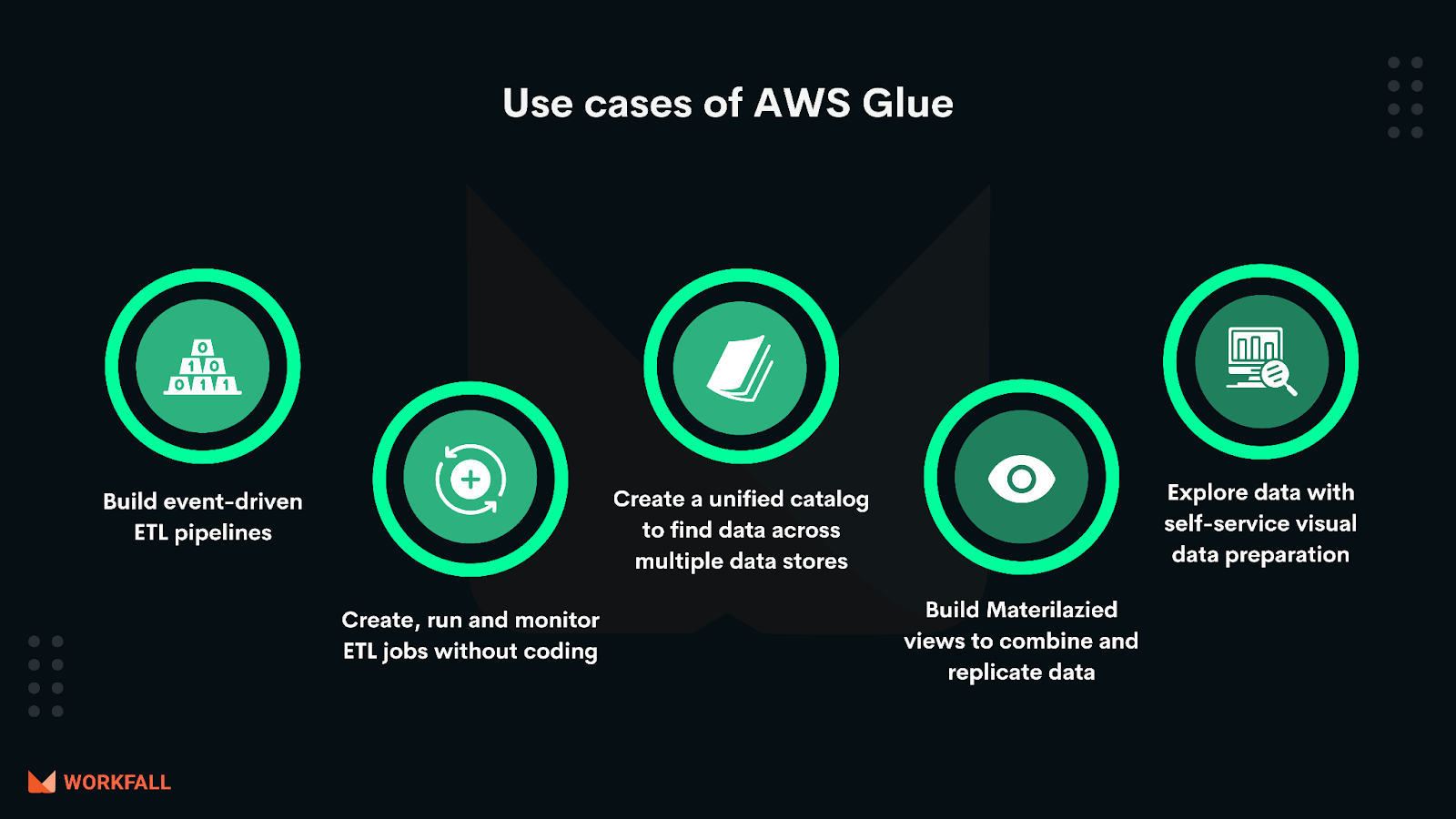
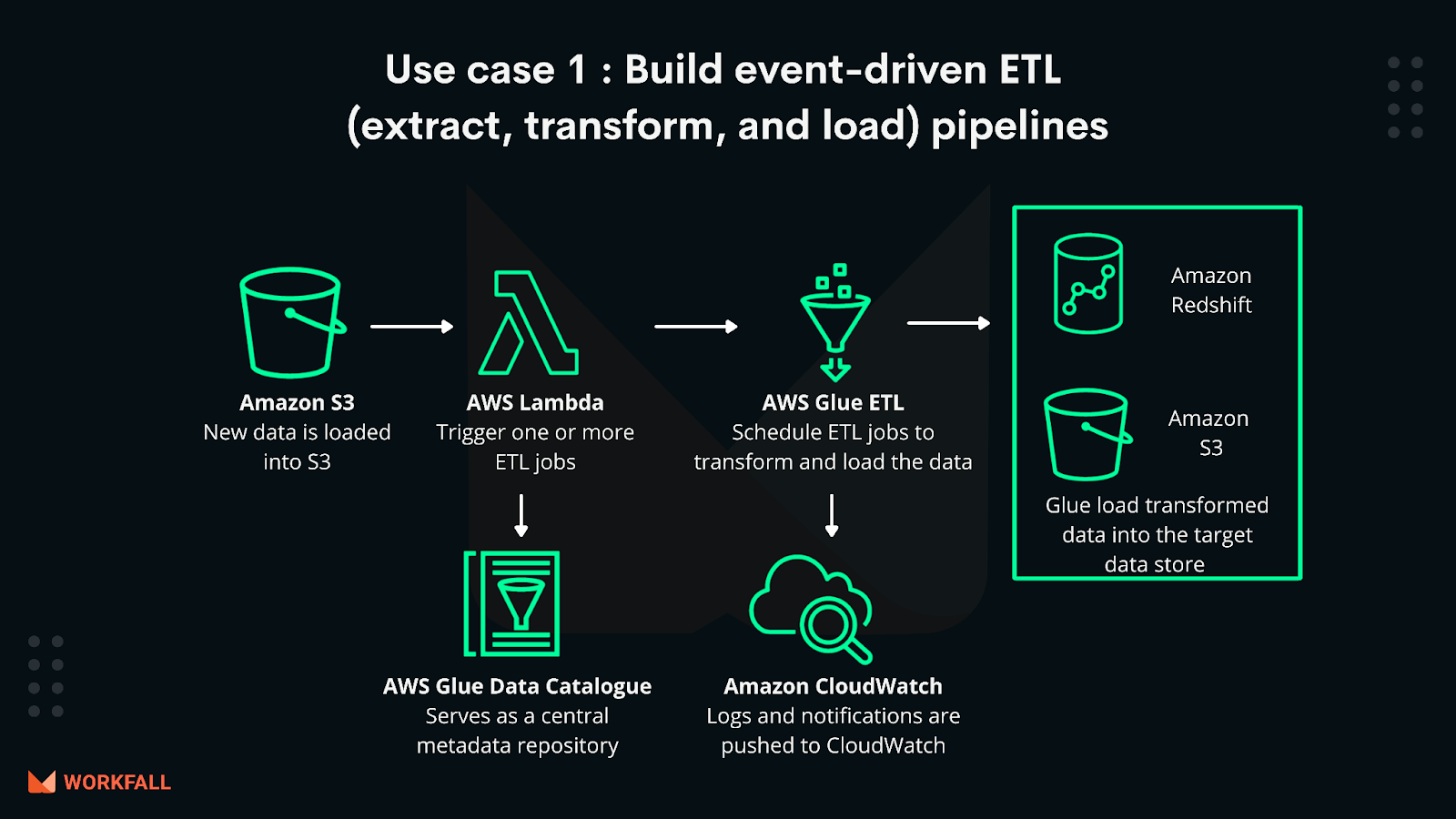
Build event-driven ETL (extract, transform, and load) pipelines: AWS Glue can run your ETL jobs as new data arrives. For example, you can use an AWS Lambda function to trigger your ETL jobs to run as soon as new data becomes available in Amazon S3. You can also register this new dataset in the AWS Glue Data Catalog as part of your ETL jobs.
Create a unified catalog to find data across multiple data stores: You can use the AWS Glue Data Catalog to quickly discover and search across multiple AWS data sets without moving the data. Once the data is cataloged, it is immediately available for search and query using Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum.

Create, run, and monitor ETL jobs without coding: AWS Glue Studio makes it easy to visually create, run, and monitor AWS Glue ETL jobs. You can compose ETL jobs that move and transform data using a drag-and-drop editor, and AWS Glue automatically generates the code. You can then use the AWS Glue Studio job run dashboard to monitor ETL execution and ensure that your jobs are operating as intended.

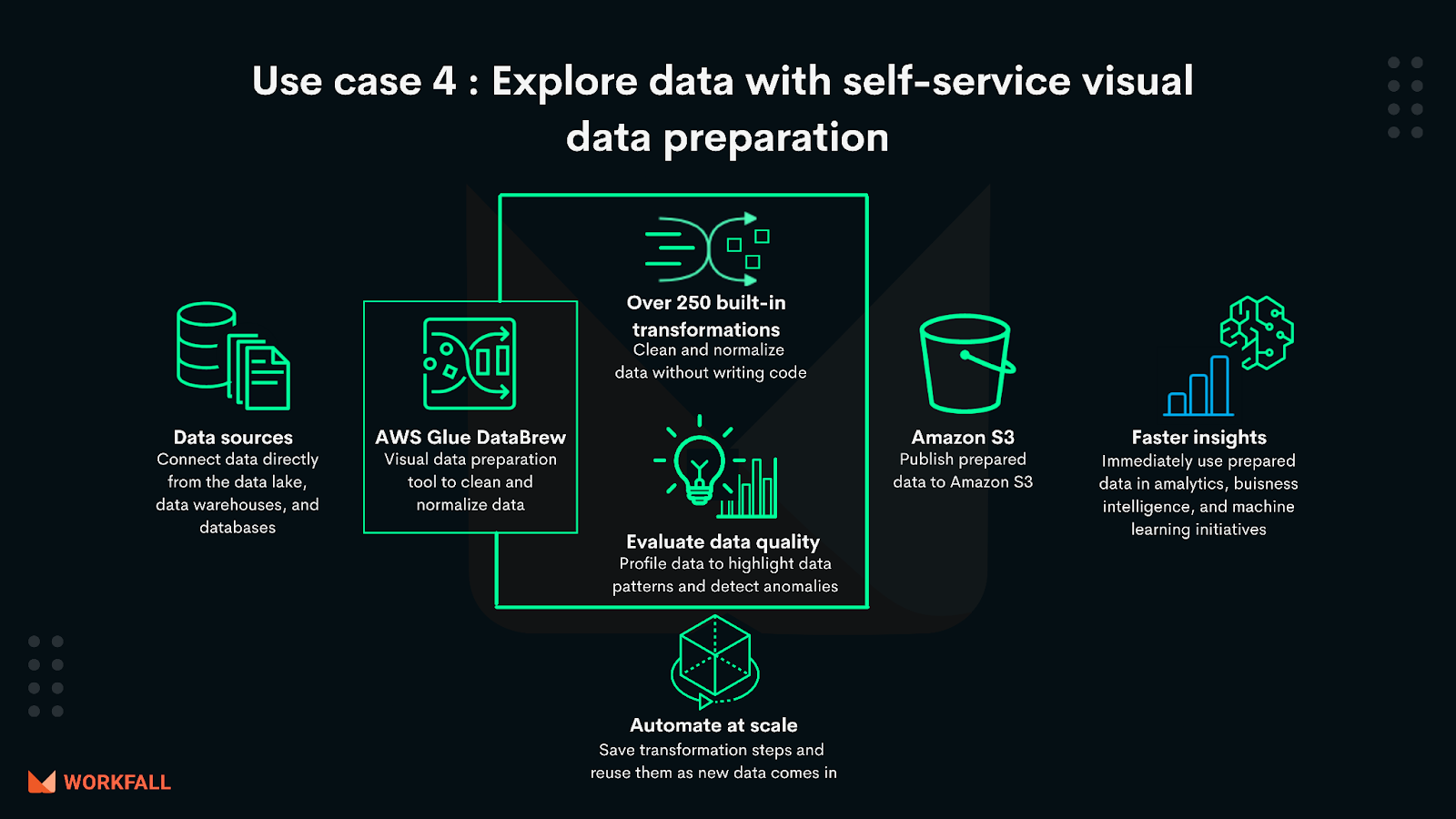
Explore data with self-service visual data preparation: AWS Glue DataBrew enables you to explore and experiment with data directly from your data lake, data warehouses, and databases, including Amazon S3, Amazon Redshift, AWS Lake Formation, Amazon Aurora, and Amazon RDS. You can choose from over 250 prebuilt transformations in AWS Glue DataBrew to automate data preparation tasks, such as filtering anomalies, standardizing formats, and correcting invalid values. After the data is prepared, you can immediately use it for analytics and machine learning.
Build materialized views to combine and replicate data: AWS Glue Elastic Views enables you to use familiar SQL to create materialized views. Use these views to access and combine data from multiple source data stores, and keep that combined data up-to-date and accessible from a target data store. The AWS Glue Elastic Views preview currently supports Amazon DynamoDB as a source, with support for Amazon Aurora and Amazon RDS to follow. Currently supported targets are Amazon Redshift, Amazon S3, and Amazon OpenSearch Service (successor to Amazon Elasticsearch Service), with support for Amazon Aurora, Amazon RDS, and Amazon DynamoDB to follow.

Features of AWS Glue
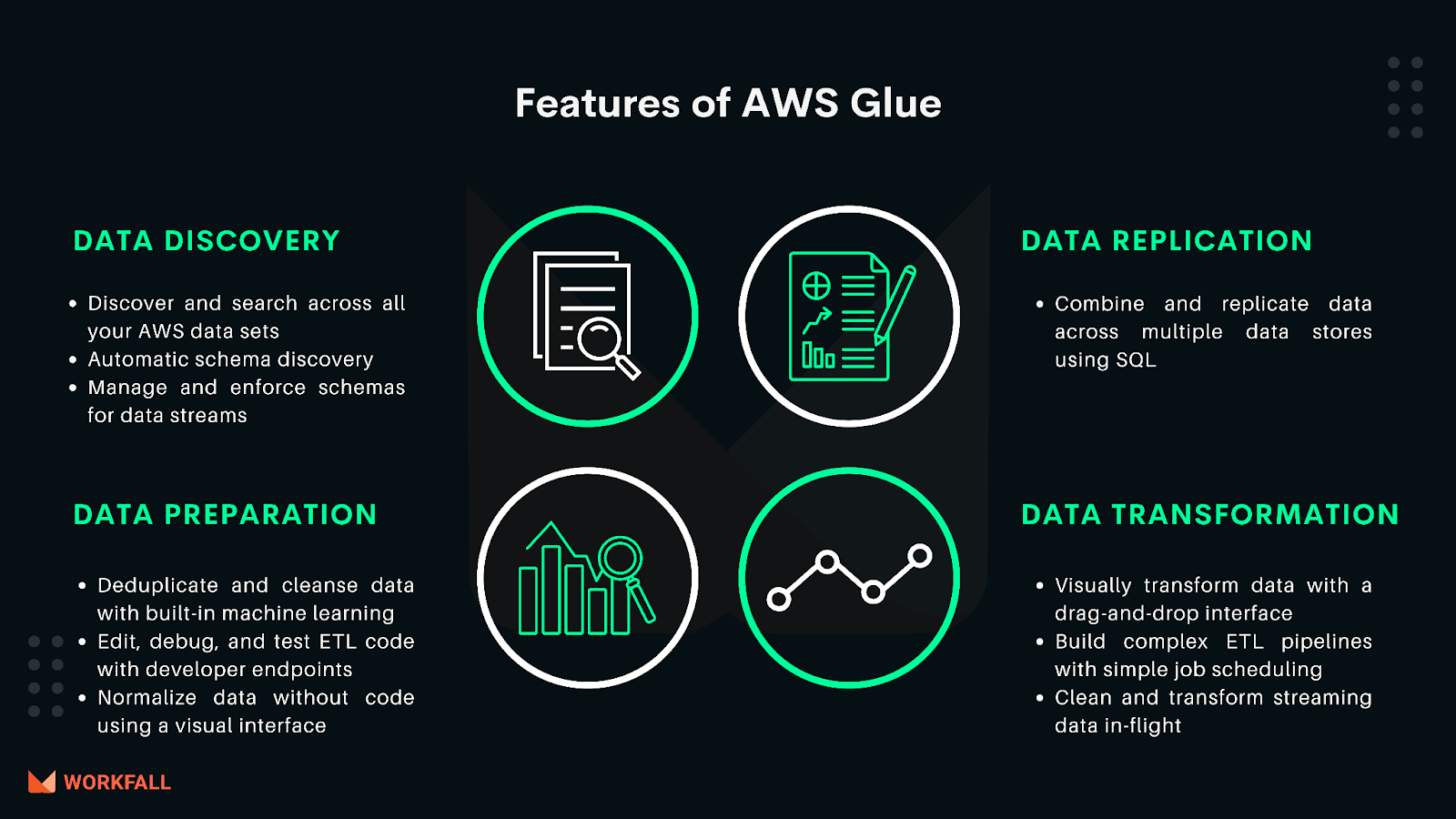
Automatic schema discovery: Glue allows developers to automate crawlers to obtain schema-related information and store it in the data catalog, which can then be used to manage jobs.
Job scheduler: Glue jobs can be set and called on a flexible schedule, either by event-based triggers or on demand. Several jobs can be started in parallel, and users can specify dependencies between jobs.
Developer endpoints: Developers can use these to debug Glue, as well as create custom readers, writers, and transformations, which can then be imported into custom libraries.
Automatic code generation: The ETL process automatically generates code, and the only input necessary is a location/path for the data to be stored. The code is in either Scala or Python.
Integrated data catalog: Acts as a singular metadata store of data from a disparate source in the AWS pipeline. An AWS account has one catalog.
When to use AWS Glue?
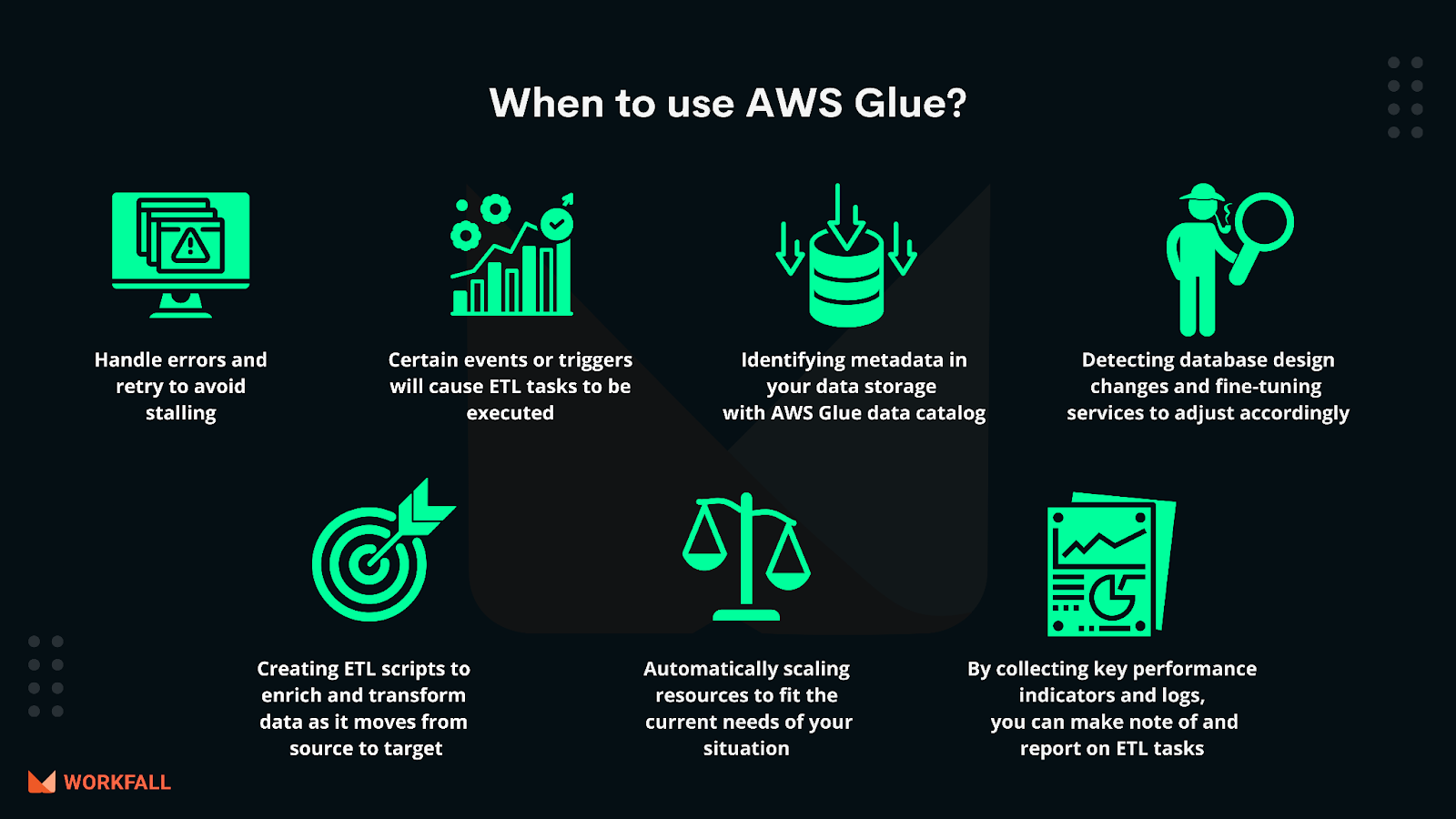
One should utilize AWS Glue to find data properties, transform them, and prepare them for analytics using AWS Glue. Glue can automatically identify both structured and semi-structured data in the Amazon S3 data lake, Amazon Redshift data warehouse, and numerous AWS databases.
One may use AWS Glue to carry out the following tasks:
- Scaling resources automatically to meet your situation’s current requirements.
- To avoid stalling, handle errors and retry.
- Monitoring and reporting your ETL activities by collecting KPIs (Key Performance Indicators), metrics, and logs.
- ETL tasks are to be executed in response to certain events, schedules, or triggers.
- Automatically detecting changes in the database schema and fine-tuning the service to adapt appropriately.
- Creating ETL scripts to enrich, denormalize, and transform data as it moves from source to target.
- Identifying the metadata in your data stores and databases, and then archiving it in AWS Glue Data Catalog.
Data sources supported by AWS Glue
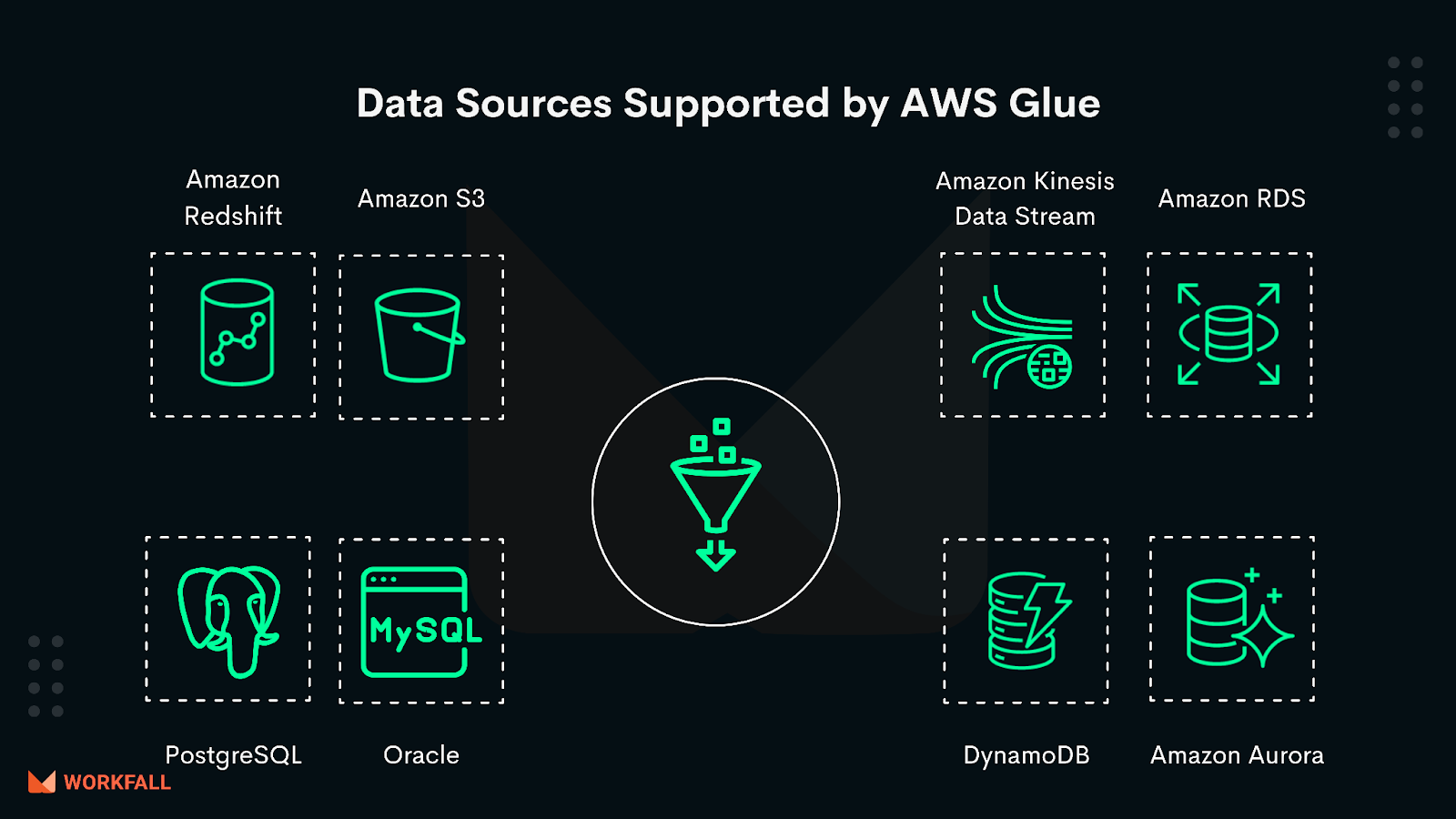
AWS Glue natively supports data in Amazon RDS, Amazon Aurora for MySQL, Amazon RDS for Oracle, Amazon RDS for PostgreSQL, Amazon RDS for PostgreSQL, Amazon RDS for SQL Server, Amazon Redshift, DynamoDB, and Amazon S3, as well as MySQL, Oracle, Microsoft SQL Server, and PostgreSQL databases in ones Amazon VPC running on Amazon EC2. AWS Glue also works with Amazon MSK, Amazon Kinesis Data Streams, and Apache Kafka data streams.
To access data sources not natively supported by AWS Glue, one can create custom Scala or Python code and import custom libraries and Jar files into AWS Glue ETL processes.
AWS Glue data pricing
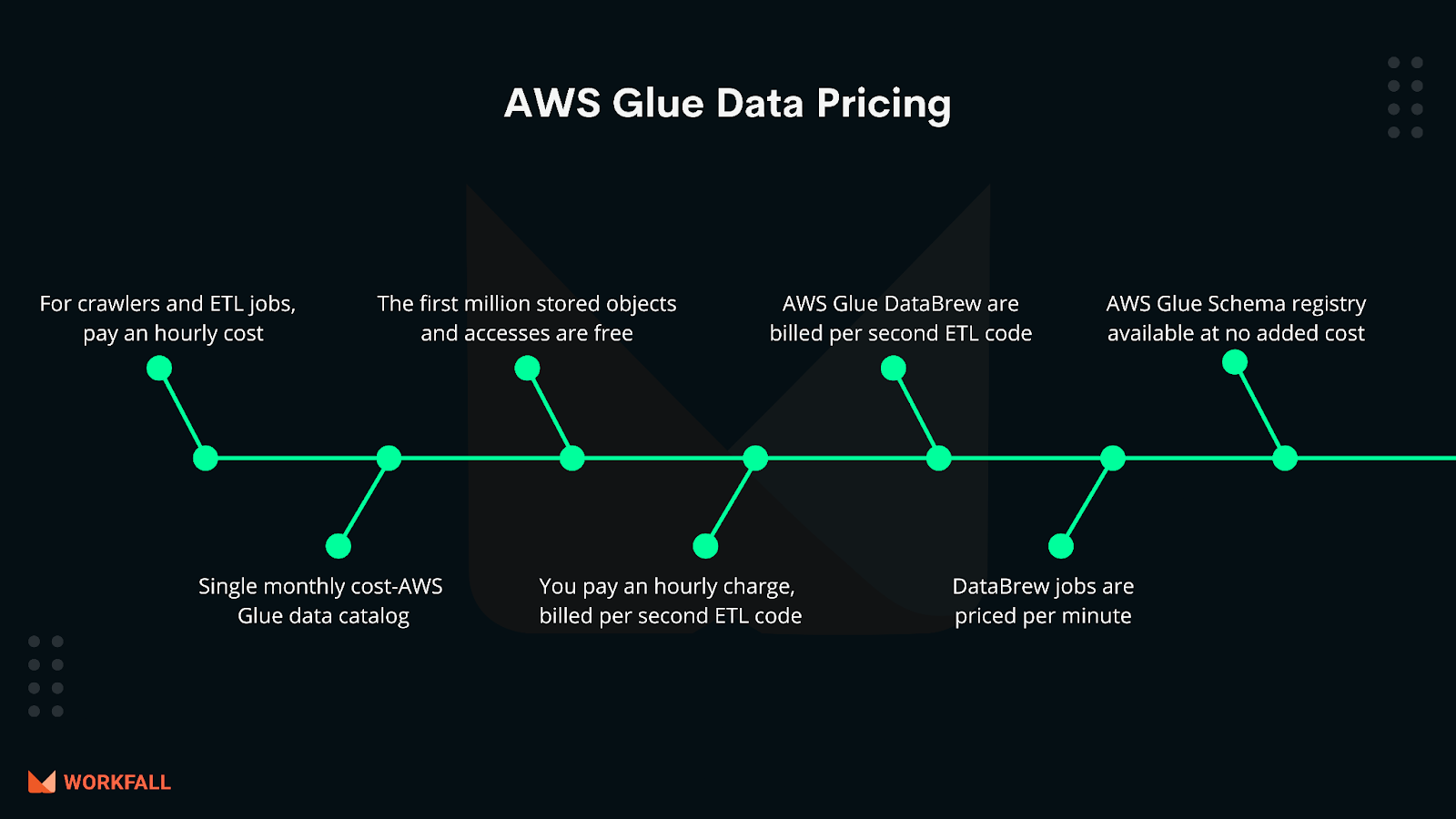
For crawlers (data discovery) and ETL jobs, you pay an hourly cost paid by the second using AWS Glue (processing and loading data). You pay a single monthly cost for storing and accessing metadata in the AWS Glue Data Catalog. The first million stored objects, as well as the first million accesses, are both free. You pay an hourly charge, billed per second, if you offer a development endpoint to interactively build your ETL code. The interactive sessions for AWS Glue DataBrew are billed per session, while the DataBrew jobs are priced per minute. The AWS Glue Schema registry is available at no additional cost. Pricing may vary by region.
Customers using AWS Glue
FinAccel
“After experimenting with different ETL frameworks, we ended up using AWS Glue to power our day-to-day ETL processes. As easy as point and click, we are able to define and run ETL jobs in no time without complicated server provisioning. ETL-ing data from our data lake to our Redshift warehouse is just one of use case examples of AWS Glue. The transformed data is then fed to our BI tools to track important key metrics, and it also serves as a basis for our credit scoring models, which have credit scored millions of customers. Last but not least, in a hyper-growth startup like us, being cost-effective is essential. AWS Glue allows us to pay only for computing power that we need to run the jobs. It is amazing that leveraging AWS Glue has enabled our small team of data engineers to run the whole data infrastructure in our company.”
Umang Rustagi, Co-founder and COO – FinAccel

Beeswax
“Beeswax uses Amazon S3 and AWS Glue Data Catalog to build a highly reliable data lake that is fully managed by Amazon Web Services. Our platform leverages the AWS Glue Data Catalog integration with Amazon EMR in Hive and SparkSQL applications to deliver reporting and optimization features to our customers.”
Ram Kumar Rengaswamy, CTO – Beeswax
Conclusion
In this blog, we have explored AWS Glue, its features, benefits, different use cases, when to use it, and data sources supported by AWS Glue. We have learned that it is a powerful cloud-based tool for working with ETL pipelines. It simplifies data extraction, transformations, and loading for Spark-fluent users. We will demonstrate the full implementation of AWS Glue with step-by-step instructions in our upcoming blog. Stay tuned to keep getting all updates about our upcoming new blogs on AWS and relevant technologies.
Meanwhile …
Keep Exploring -> Keep Learning -> Keep Mastering
This blog is part of our effort toward building a knowledgeable and kick-ass tech community. At Workfall, we strive to provide the best tech and pay opportunities to AWS-certified talents. If you’re looking to work with global clients and build kick-ass products while making big bucks doing so, give it a shot at workfall.com/partner today.


