We are in the data age, so along with data creation and retrieval, storing and archiving data is equally important. For ages, storing and archiving data is always costly! We generally overpay for data archiving because we are forced to make an expensive upfront payment for archiving solutions.
Since we have to guess what our capacity requirements will be, we understandably over-provision to make sure we have enough capacity for data redundancy and unexpected growth. These circumstances result in the underutilization of capacity and money waste.
To get a cost-effective archive storage solution, we need some archive services that we can use on a pay-per-use basis! Sounds interesting right?
Amazon S3 Glacier is a secure cloud storage service for data archiving and backup. While using Amazon S3 Glacier, you pay only for what you use. Amazon S3 Glacier changes the game for data archiving and backup as we pay nothing upfront, and pay a very low price for storage. This made AWS Glacier the best choice to store and archive data.
In this blog, we will have a look at different storage options provided by AWS followed by detailed information and implementation of S3 Glacier, a secure, durable, and extremely low-cost Amazon S3 storage class for data archiving and long-term backup.
In this blog, we will cover:
- AWS Storage Services
- Which Storage service is the best fit for your storage need?
- What is Amazon S3 Glacier and why do we need it?
- Features of Amazon S3 Glacier
- Amazon S3 Glacier Data model
- Types of retrieval policies in the AWS S3 Glacier
- Benefits of Amazon S3 Glacier
- Use cases of Amazon S3 Glacier
- Companies using Amazon S3 Glacier
- Amazon S3 Glacier pricing
- Hands-on
- Conclusion
AWS Storage Services
Amazon Web Services (AWS) provides low-cost data storage with high durability and availability. AWS offers storage choices for backup, archiving, and disaster recovery use cases.
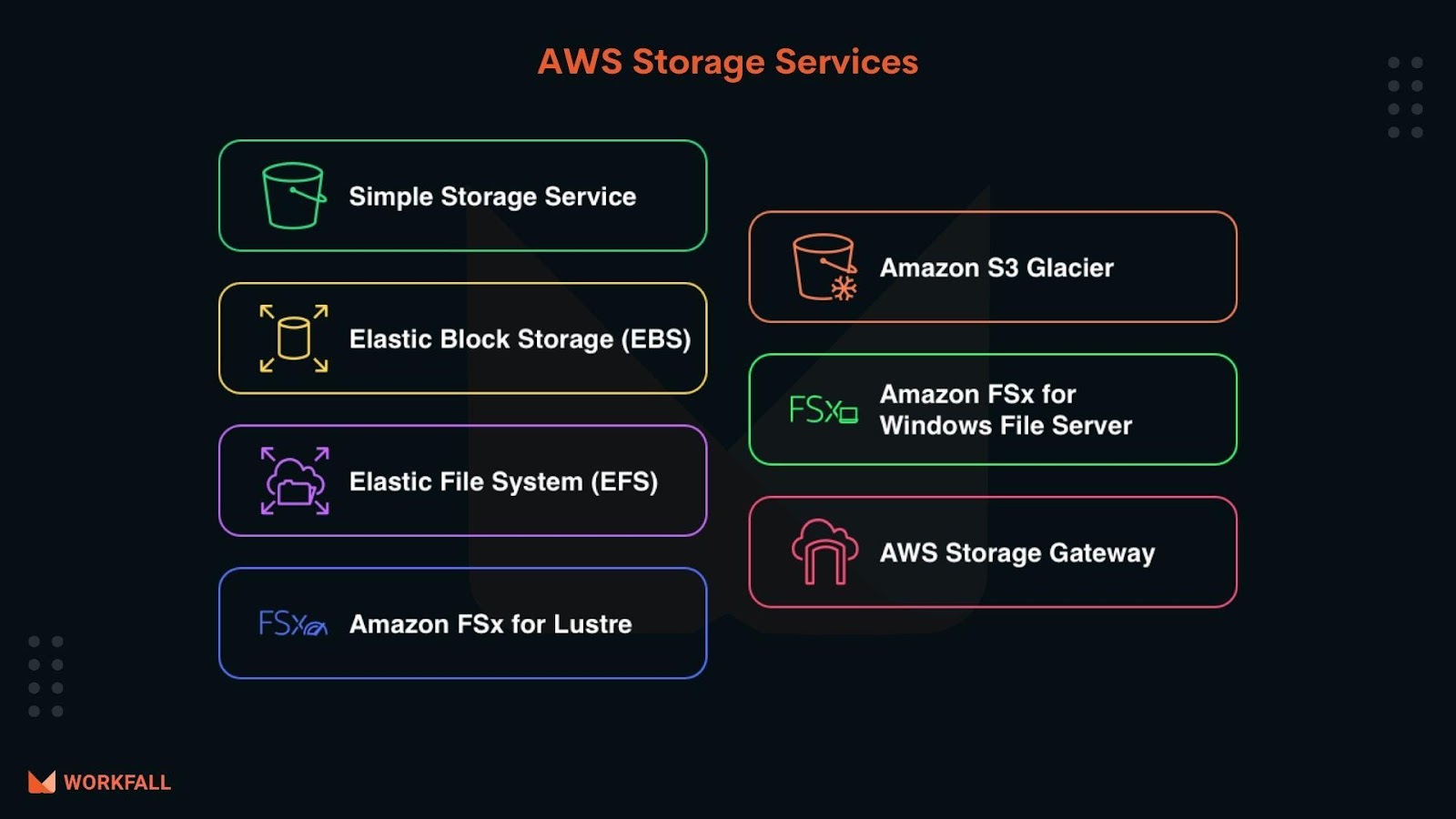
There are majorly following types of storage options available in AWS such as :
- Object Storage: Object storage takes each piece of data and designates it as an object. Data is kept in separate storehouses associated with metadata and a unique identifier to form a storage pool.

It is an object storage service that offers high scalability, data availability, security, and performance. It can be used to store and protect any amount of data for a range of use cases, such as data lakes, websites, mobile applications, backup and restore, archive, enterprise applications, IoT devices, and big data analytics.
- File Storage: Storing data as a single piece of information in a folder helps us in organizing it among other data. This is also called hierarchical storage. Following are the different file storage types:
Amazon Elastic File System
Amazon Elastic File System (Amazon EFS) provides a fully managed elastic NFS file system for use with AWS Cloud services and on-premises resources. Amazon EFS is designed to provide massively parallel shared access to thousands of Amazon EC2 instances, enabling your applications to achieve high levels of aggregate throughput and IOPS with consistently low latencies.
Amazon FSx for Windows
Amazon FSx for Windows File Server provides file storage that is accessible over the Server Message Block (SMB) protocol. Amazon FSx file storage is accessible from Windows, Linux, and macOS compute instances and devices running on AWS or on-premises.
Amazon FSx for Lustre
The world’s most popular high-performance file system, FSx for Lustre offers sub-millisecond latencies. It provides cost-effective, high-performance, scalable storage for compute workloads such as machine learning, high-performance computing (HPC), video rendering, etc.
- Block Storage: The data is stored in blocks/sectors identifiable by the block/sector ID. The data is stored in blocks/sectors identifiable by the block/sector ID. EBS is an example of Block storage.
Amazon Elastic Block Store (EBS)
Amazon Elastic Block Store (EBS) is an easy-to-use, high-performance, block-storage service designed for use with Amazon Elastic Compute Cloud (EC2) for both throughput and transaction-intensive workloads at any scale.
- Data transfer: Cloud data transfer services can simplify transferring data into the cloud by addressing high network costs, long transfer times, and security concerns. Storage Gateway is an example of data transfer.
- Storage Gateway: AWS Storage Gateway is a cloud storage service that gives us on-premises access to virtually cloud storage. Storage Gateway offers three different types of gateways – File Gateway, Tape Gateway, and Volume Gateway – that seamlessly connect on-premises applications to cloud storage, caching data locally for low-latency access.
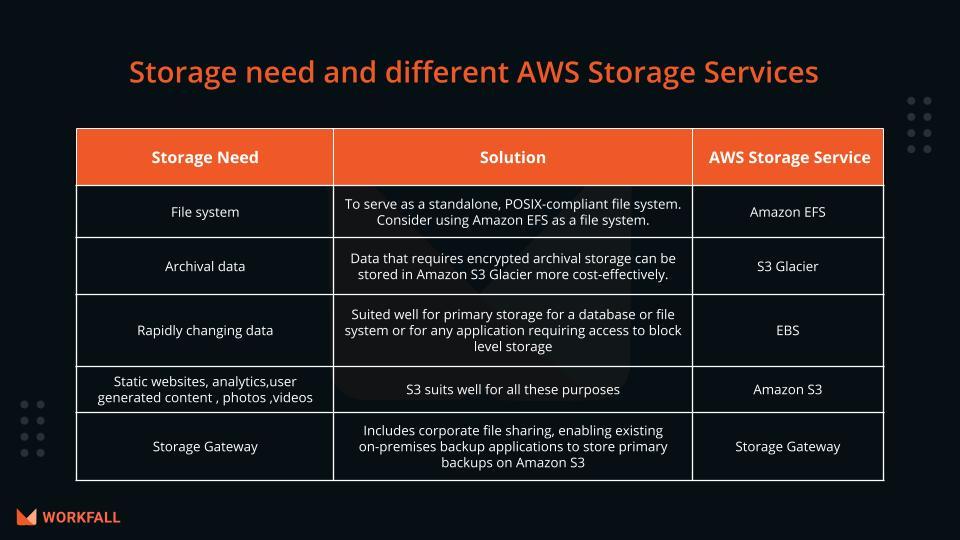
Which Storage service is the best fit for your storage need?
Based on your choice of access method (block, file, object, etc.), access pattern( sequential or random), frequency of access (offline, online, archival), availability, and durability you can choose an optimal storage solution.
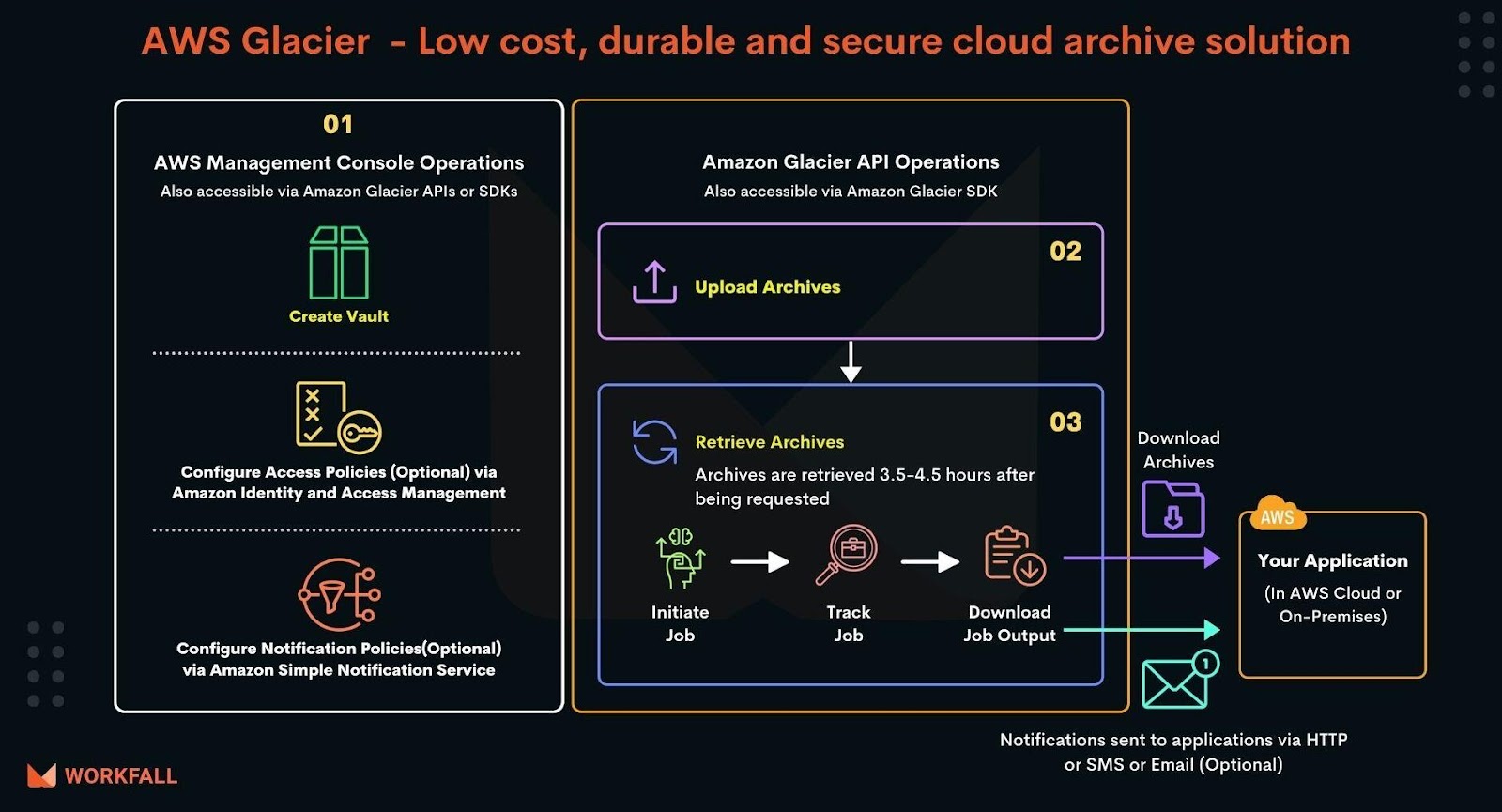
What is Amazon S3 Glacier and why do we need it?

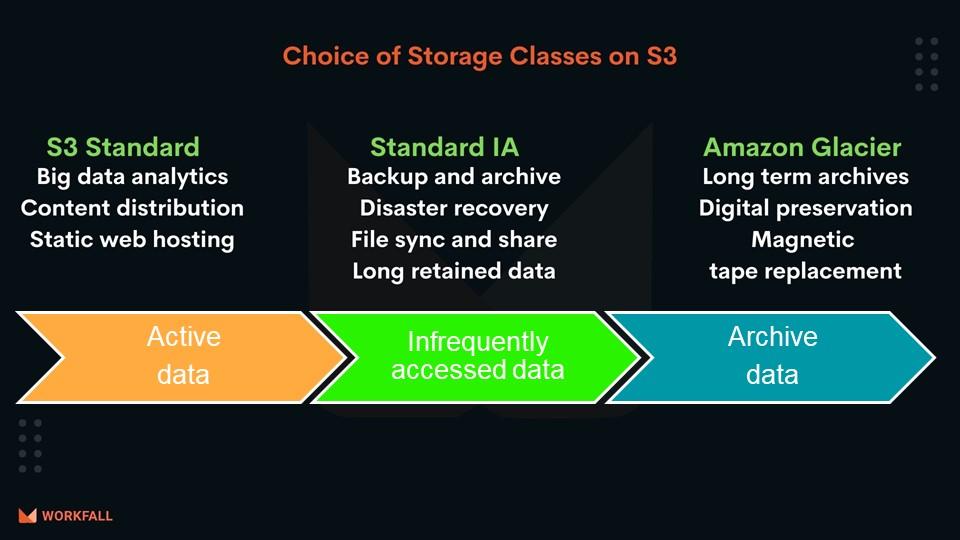
S3 Glacier is one of the many different storage classes for Amazon S3. Amazon S3 Glacier and S3 Glacier Deep Archive are secure, durable, and extremely low-cost Amazon S3 cloud storage classes for data archiving and long-term backup. Amazon Glacier is optimized for data that is infrequently accessed and for which retrieval times of several hours are suitable. S3 Glacier enables customers to offload the administrative burdens of operating and scaling storage to AWS, so they don’t have to worry about capacity planning, hardware provisioning, data replication, hardware failure detection, recovery, etc.
Features of Amazon S3 Glacier
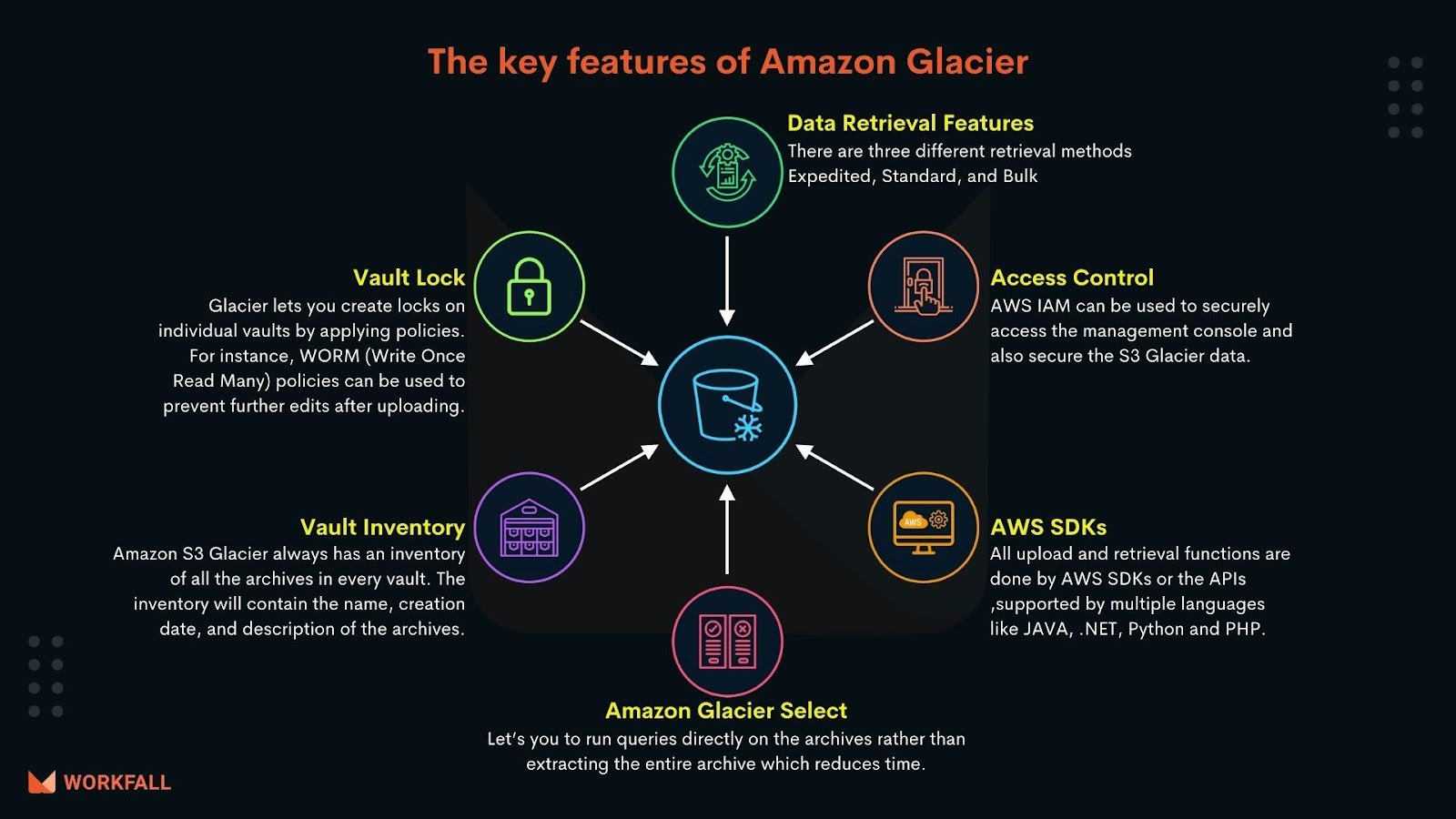
The key features of Glacier are as follows :
- Data Retrieval features
There are three different retrieval methods – Expedited, Standard, and Bulk
- Amazon Glacier select
Let’s run queries directly on the archives rather than extracting the entire archive which reduces time.
- Vault lock
Glacier lets you create locks on individual vaults by applying policies. For instance, WORM (Write Once Read Many) policies can be used to prevent further edits after uploading.
- Access control
AWS IAM can be used to securely access the management console and also secure the S3 Glacier data.
- Vault inventory
Amazon S3 Glacier always has an inventory of all the archives in every vault. The inventory will contain the name, creation date, and description of the archives.
- AWS Software Development Kits (SDKs)
All upload and retrieval functions are done by AWS SDKs or the APIs, supported by multiple languages like JAVA, .NET, Python, and PHP.
Amazon S3 Glacier Data model
The Amazon S3 Glacier (S3 Glacier) data model core concepts include vaults and archives. S3 Glacier is a REST-based web service. In terms of REST, vaults and archives are the resources. In addition, the S3 Glacier data model includes job and notification configuration resources.
Vault: It is a container for storing archives and allows unlimited storage. Glacier supports various vault operations which are region specific
Archive: An archive can be any data like photos, videos, or documents and is a base unit of storage in Glacier. Glacier assigns the archive an ID, which is unique in the AWS region in which it is stored. The archive can be uploaded in a single request. Glacier also provides a multipart upload API that enables uploading an archive in parts for large archives,
Jobs: A Job is required to retrieve an Archive and vault inventory list. Data retrieval requests are asynchronous operations, are queued and most jobs take a few hours to complete. A job is first initiated and when the job is complete, then the output of the job is downloaded in full or partially by specifying a byte range.
Notification Configuration: As the jobs are asynchronous, Glacier supports a notification mechanism to an SNS topic when the job completes.
Types of retrieval policies in the AWS S3 Glacier
Glacier provides three options for retrieving data with varying access times and costs: Expedited, Standard, and Bulk retrievals.
Standard retrievals: allow access to any of the archives within several hours. It typically completes within 3-5 hours.
Bulk retrievals: are Glacier’s lowest-cost retrieval option, enabling retrieval of large amounts, even petabytes, of data inexpensively in a day. It typically completes within 5 – 12 hours.
Expedited retrievals: allow quick access to the data when occasional urgent requests for a subset of archives are required. For all the largest archives, data accessed using Expedited retrievals are typically made available within 1 to 5 minutes.
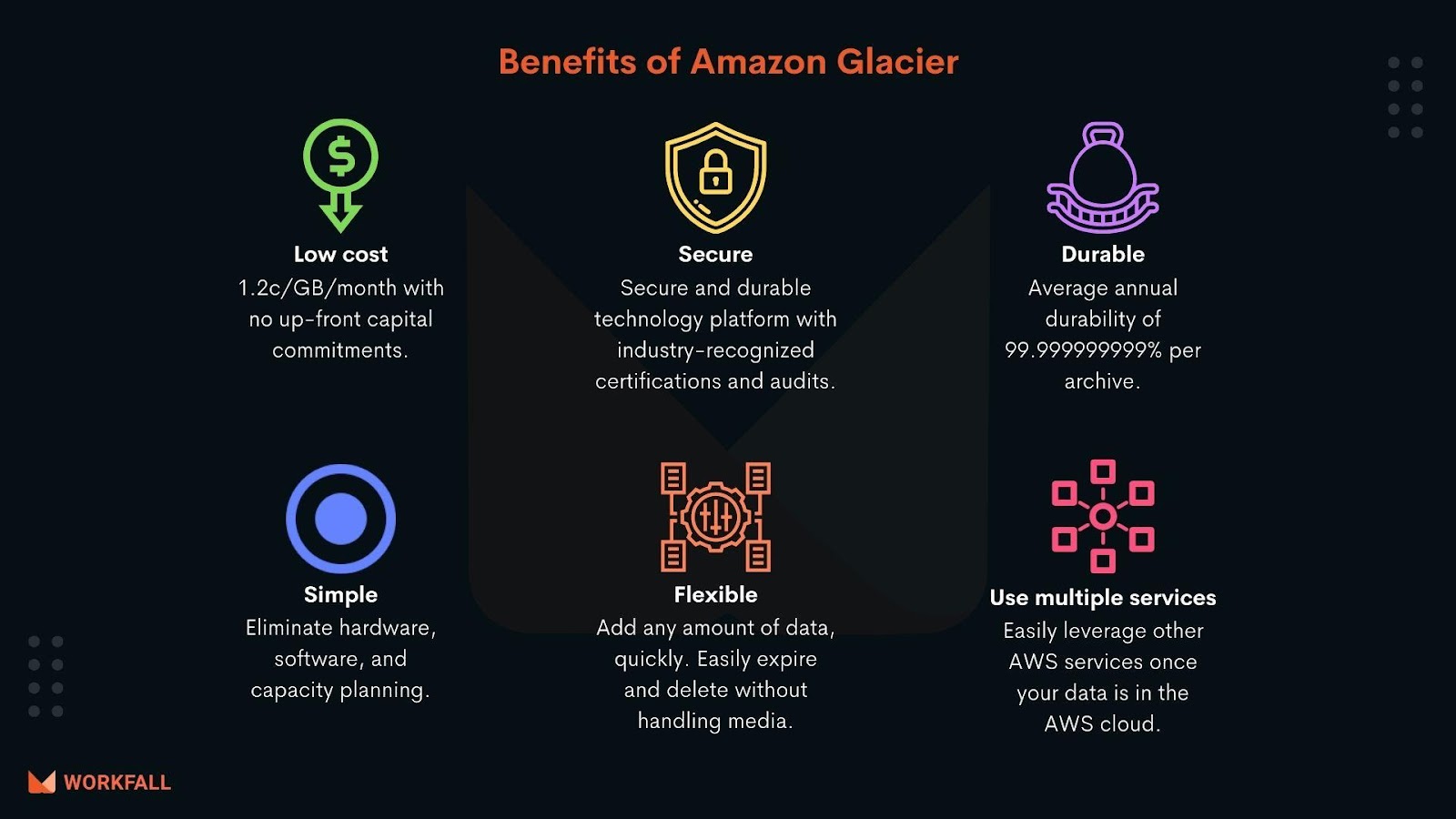
Benefits of Amazon S3 Glacier
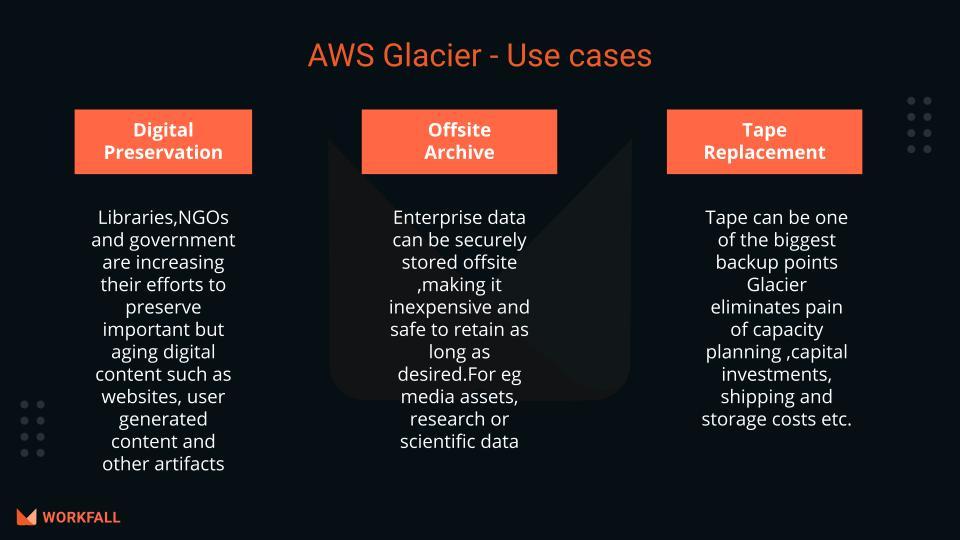
Use cases of Amazon S3 Glacier
Companies using Amazon S3 Glacier

Amazon S3 Glacier pricing
You can retrieve up to 10 GB of your Amazon S3 Glacier data per month for free.
Amazon S3 Glacier pricing is region specific. Here are the details of the pricing for the Singapore region.

Hands-On
In this hands-on, we’ll see how to create an s3 glacier vault to store and archive our data.
Step 1: Open AWS Management Console and go to Amazon S3 Glacier service. After that click on “create vault” to move forward.
Step 2: There are 4 steps normally. First, choose the Region and then provide a name for your vault. Then click on “Next step”
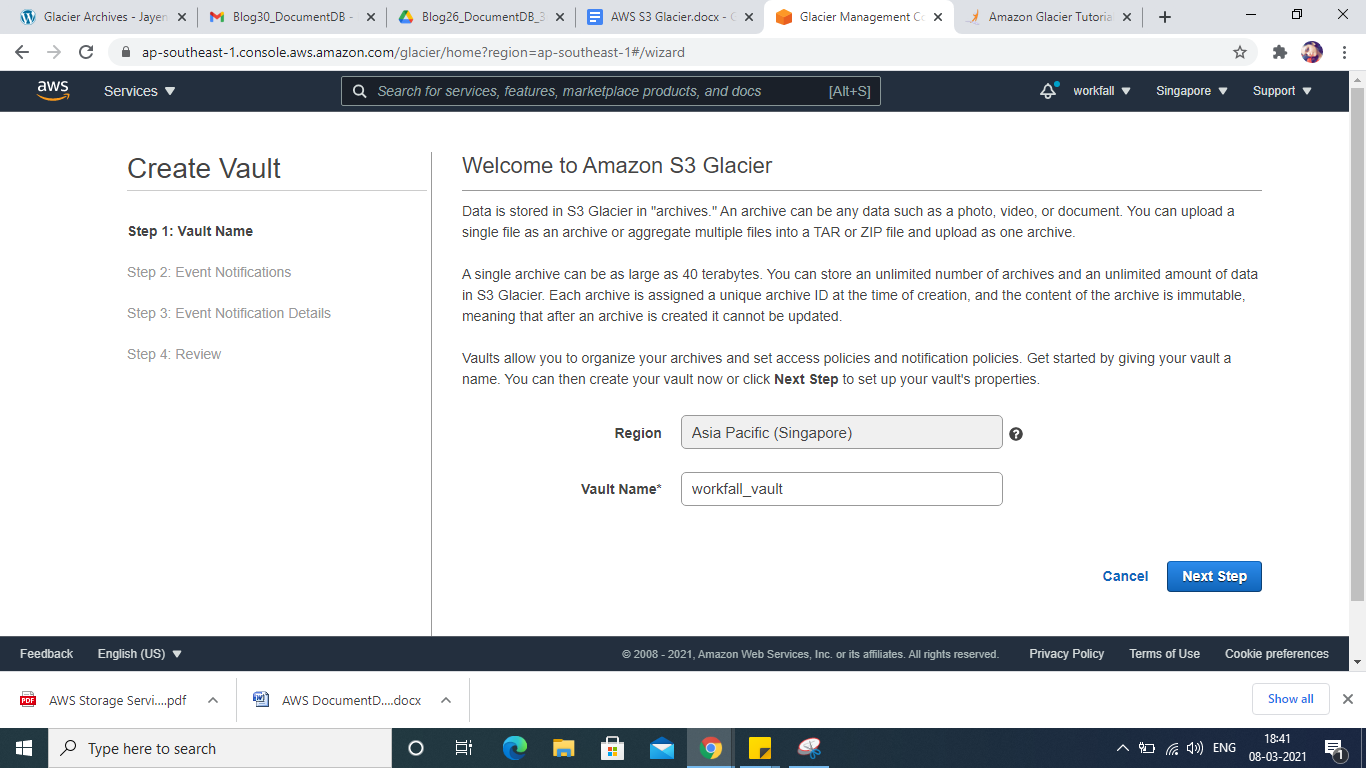
Step 3: Click on Do not enable notifications and click Next

Step 4: Review the content and click on “Submit”.
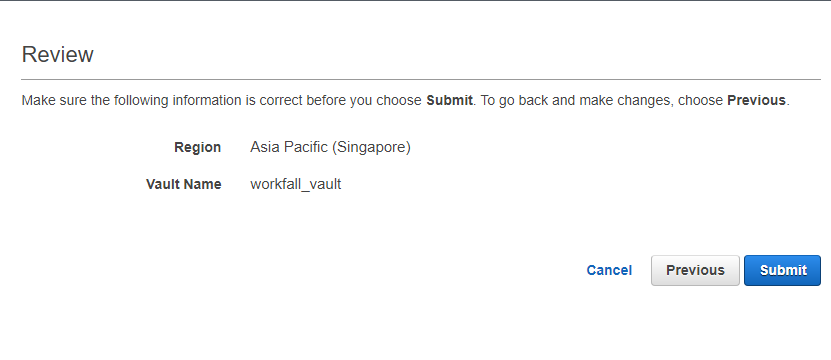
Step 5: An Amazon S3 Glacier vault has been successfully created.
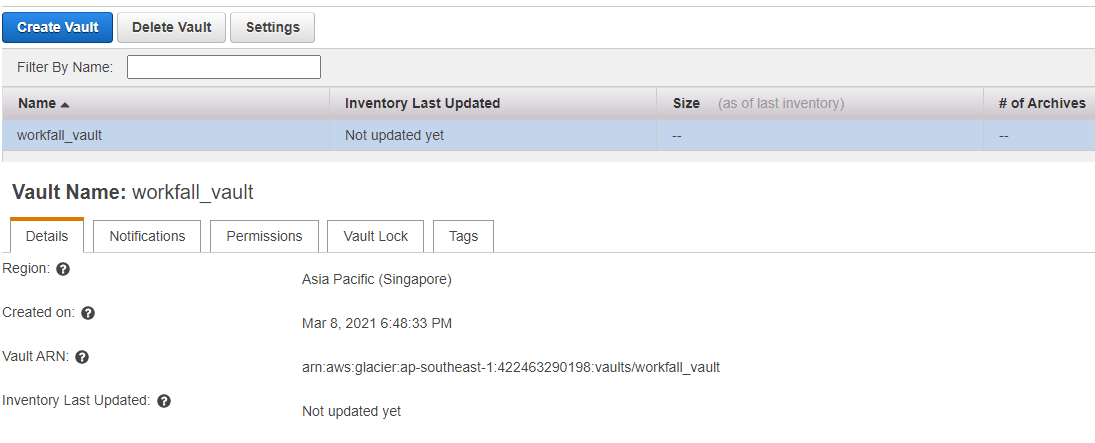
Step 6: Click on Setting to view and change the Retrieval Policies.Have set it to ”Free tier “ and save it
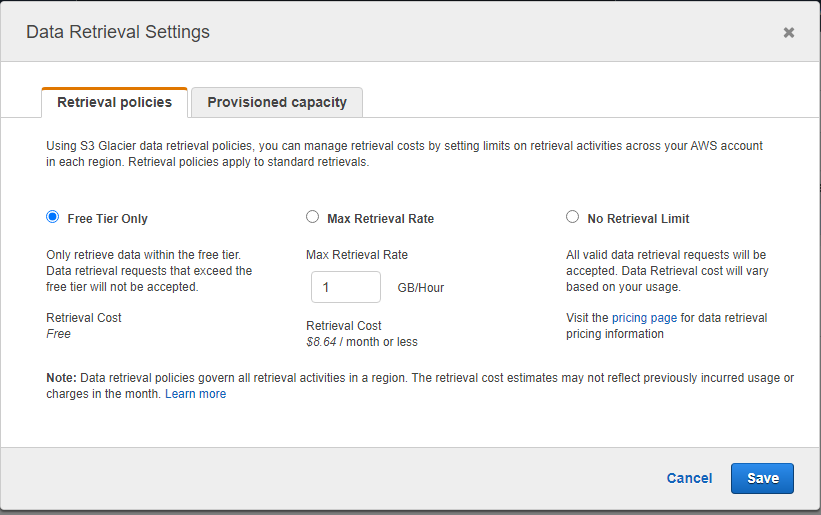
The next step is to: Specify a compliance policy for your vault
Amazon Glacier Vault Lock allows you to easily deploy and enforce compliance controls for individual Amazon Glacier vaults with a vault lock policy. You can specify controls such as “write once read many” (WORM) in a vault lock policy and lock the policy from future edits. Once locked, the policy can no longer be changed. A vault lock policy is different from a vault access policy.
Both policies govern access controls to your vault. However, a vault lock policy can be locked to prevent future changes, providing strong enforcement for your compliance controls. You can use the vault lock policy to deploy regulatory and compliance controls, which typically require tight controls on data access. In contrast, you use a vault access policy to implement access controls that are not compliance related, temporary, and subject to frequent modification.
Locking a vault takes two steps:
- Initiate the lock by attaching a vault lock policy to your vault, which sets the lock to an in-progress state and returns a lock ID. While in the progress state, you have 24 hours to validate your vault lock policy before the lock ID expires.
- Use the lock ID to complete the locking process. If the vault lock policy doesn’t work as expected, you can abort the lock and restart from the beginning.
To add Vault Lock Policy follow the below steps:
Example 1: Deny Deletion Permissions for Archives Less Than 200 Days Old
Suppose that you have a requirement to retain archives for up to 200 days before you can delete them. You can do that by implementing the following Vault Lock policy. The policy denies the glacier:DeleteArchive action on the workfall_vault if the archive being deleted is less than 200 days old. The policy uses the Amazon Glacier-specific condition key ArchiveAgeInDays to enforce the retention requirement.
- Add the policy and click on Initiate vault lock
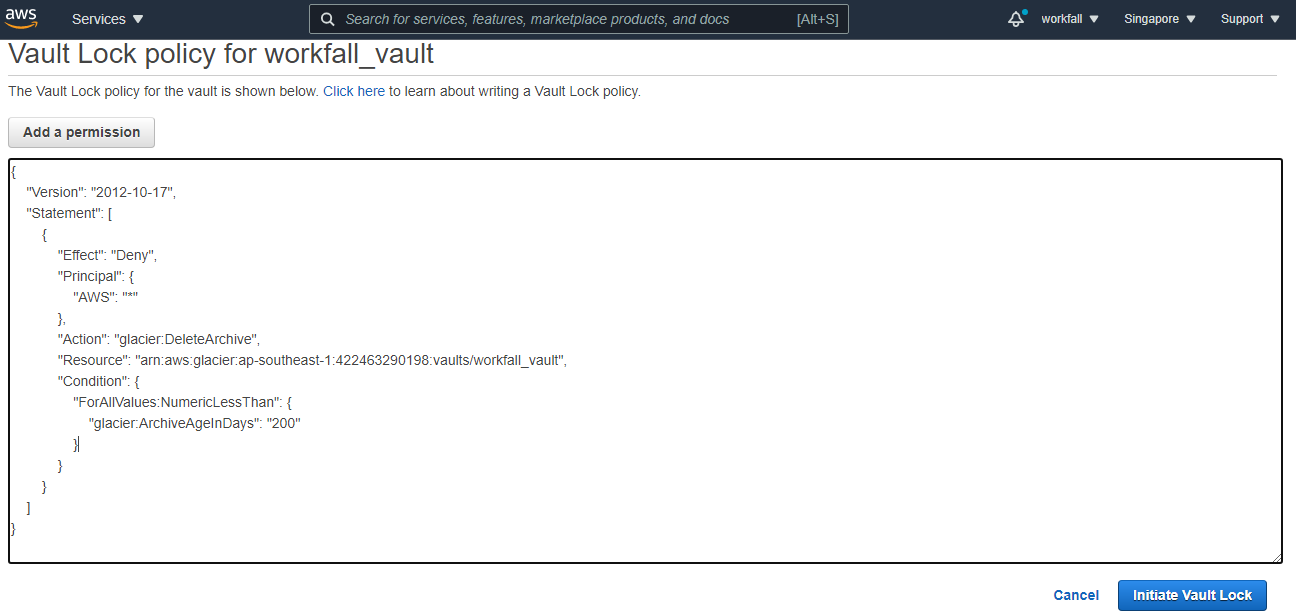
- A lock id gets generated, if the policy is not validated within 24 hrs, it will get deleted.
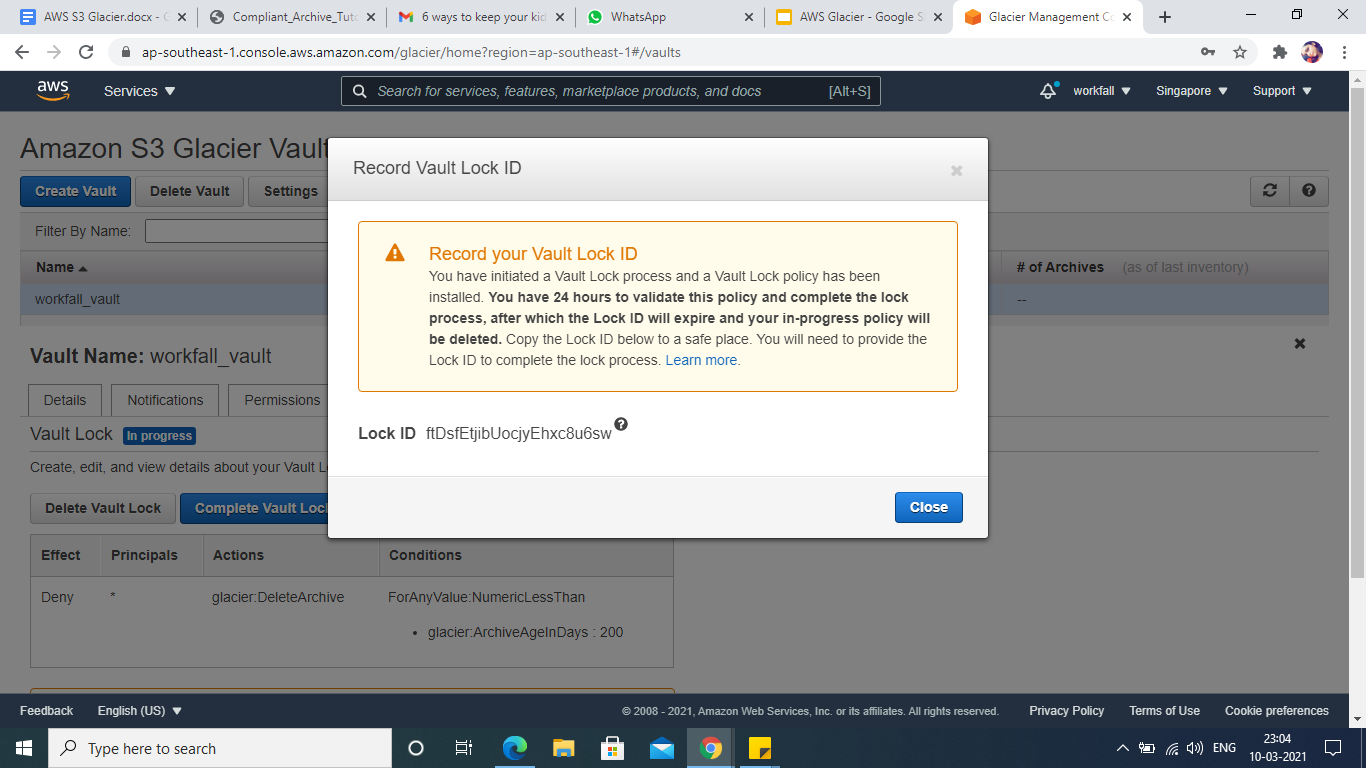
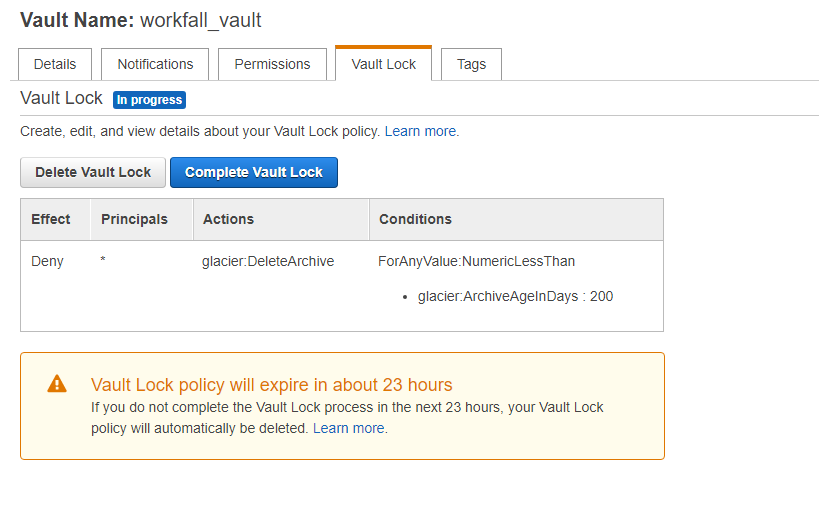
- This is how the policy looks like after it gets created, status is: in progress
Example 2: Deny Deletion Permissions Based on a Tag
Suppose that you need to place a hold on your archives to prevent deletion or modification for an indefinite duration during an investigation. So we can prevent the archive from being deleted by using the tag constraint.
It denies deletion permissions to everyone, locking the vault. This lock is performed by using the Hold string as key and value as true.
The policy uses the Amazon Glacier-specific condition key glacier:ResourseTag to enforce the retention requirement.
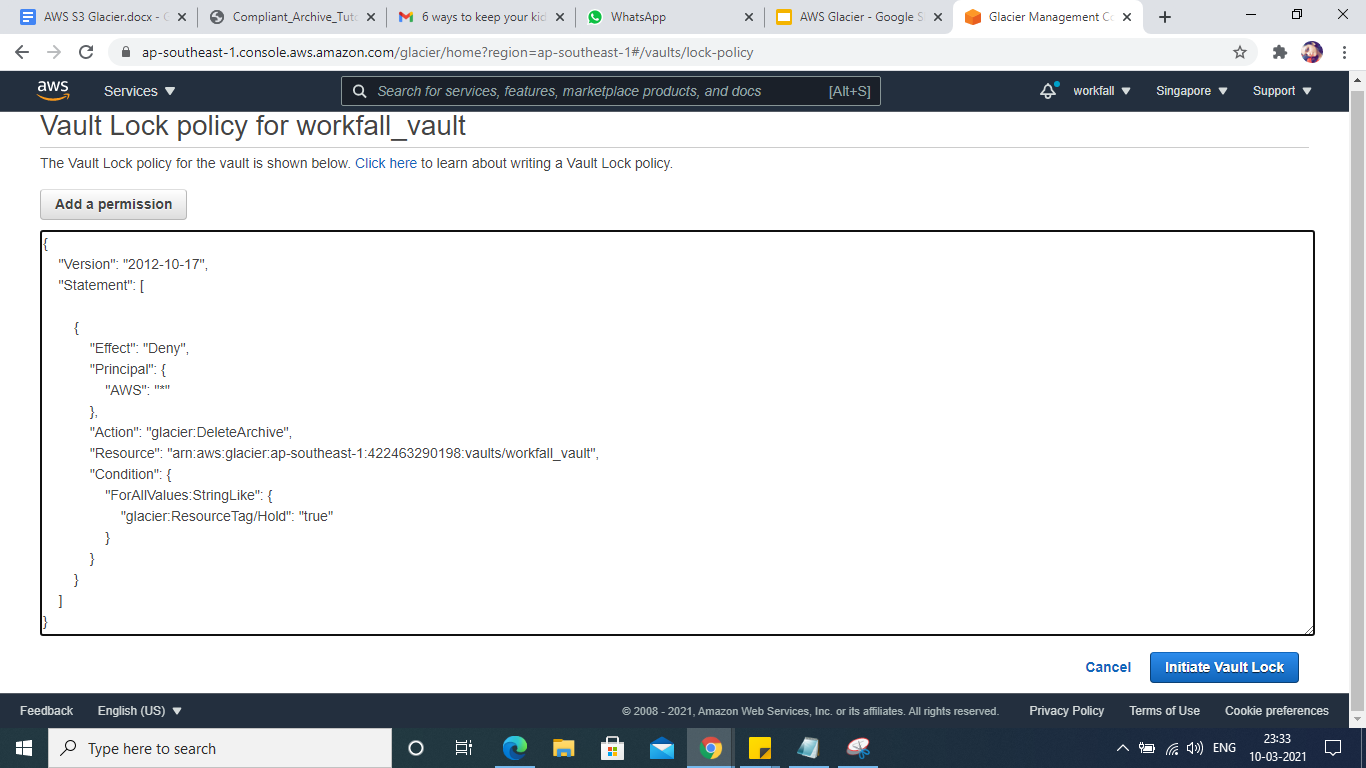
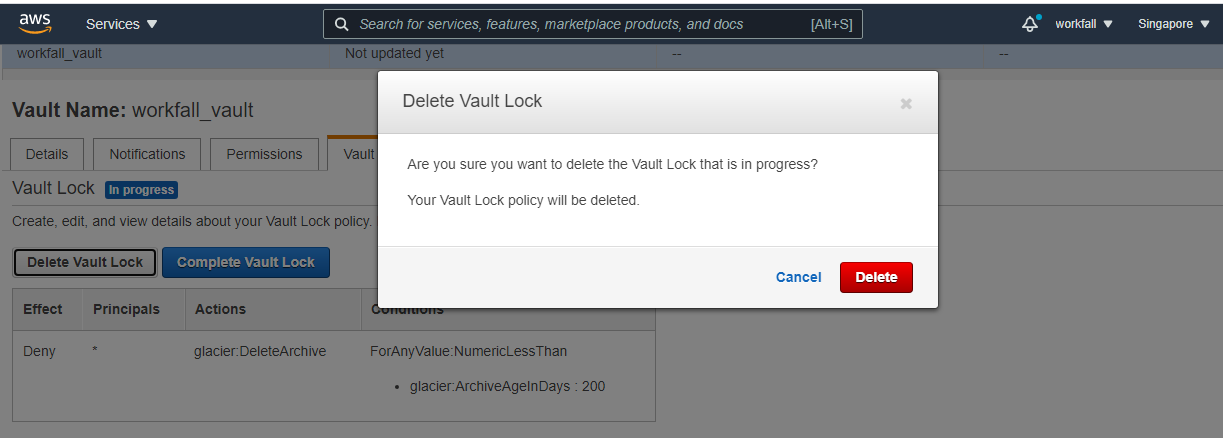
- To delete the policy, click on the Delete Vault lock and then click Delete
This is how you create an Amazon Glacier Vault. That’s all about Amazon S3 Glacier. Now it is in your hands how you are going to use it.
Conclusion
In this blog, we had a look at the different storage options provided by AWS. We also discussed which storage option is the best fit depending on the requirement of the work. We did a deep dive into AWS S3 Glacier, its features and benefits, and also the different retrieval policies available in it and also implemented the S3 Glacier vault in hands-on. S3 Glacier Deep Archive has a price point that not only is the lowest currently available for cloud storage but is also competitive with the price of offsite tape storage. We will have a look at other storage options provided by AWS in our next blogs. Stay tuned to keep getting all updates about our upcoming new blogs on AWS and relevant technologies.
Meanwhile …
Keep Exploring -> Keep Learning -> Keep Mastering
This blog is part of our effort towards building a knowledgeable and kick-ass tech community. At Workfall, we strive to provide the best tech and pay opportunities to AWS-certified talents. If you’re looking to work with global clients, build kick-ass products while making big bucks doing so, give it a shot at workfall.com/partner today.


