
In the world of data engineering, a mighty tool called DBT (Data Build Tool) comes to the rescue of modern data workflows. Imagine a team of skilled data engineers on an exciting quest to transform raw data into a treasure trove of insights.
With DBT, they weave powerful SQL spells to create data models that capture the essence of their organization’s information. DBT’s superpowers include seamlessly connecting with databases and data warehouses, performing amazing transformations, and effortlessly managing dependencies to ensure high-quality data.
As the team progresses on its journey, they witness the magic of DBT: automating their pipelines, scaling effortlessly, and fostering collaboration. Each successful deployment enriches its data ecosystem, empowering decision-makers with valuable, up-to-date insights. DBT has become the stuff of legends, passed down through generations of data engineers, forever celebrated for its role in creating a world of data excellence.
In this blog, we will cover:
- DBT Overview
- Snowflake Overview
- DBT With Snowflake
- Hands-On
- Understanding DBT Project Structure
- Creating Your First Model
- Conclusion
DBT Overview
In the magical world of DBT, there are three key concepts that bring order and clarity to the realm of data: models, transformations, and tests. Imagine a grand library within the castle, filled with books representing different datasets. Each book is a model in DBT, representing a table or a view that holds specific data. These models serve as the building blocks of analysis, providing a structured and organized representation of information.
Now, let’s talk about the data transformations. Picture a room in the castle where skilled artisans work tirelessly to refine and shape raw materials into exquisite artworks. In DBT, transformations are like these artisans. They use SQL spells to modify and enhance the data within the models. Transformations can be as simple as filtering rows or as complex as joining multiple tables together. They help create a cohesive and meaningful structure for analysis, allowing data practitioners to unlock valuable insights.
Lastly, imagine a group of vigilant guards patrolling the castle’s corridors, ensuring the safety and accuracy of the data. These guards are tests in DBT. They are responsible for verifying the quality and integrity of the data within the models and transformations. Tests act as powerful spells, validating the data against predefined criteria and ensuring it meets the expected standards. They help identify any inconsistencies or errors, giving confidence to the data users that they can trust the insights generated.
Now, let’s explore how DBT integrates with databases and data warehouses. Think of DBT as a magical bridge connecting the castle with the outside world. DBT seamlessly integrates with popular databases and data warehouses, such as PostgreSQL, BigQuery, Redshift, and Snowflake. It leverages the power and scalability of these platforms to execute its SQL spells and transform the data.
DBT also takes advantage of the strengths of these databases, such as their query optimization and indexing capabilities, to deliver efficient and high-performance data transformations. By integrating with databases and data warehouses, DBT ensures that the analysis is conducted on reliable and scalable foundations, enabling data practitioners to unlock the full potential of their data and make informed decisions.
Snowflake Overview
Snowflake is a cloud-based data warehousing platform for storing and analyzing large amounts of data. Its architecture separates storage and computing, enabling independent scaling. It supports structured and semi-structured data, with compatibility for various data formats. Snowflake provides automatic scaling, concurrency control, and workload isolation for efficient data processing. It integrates with popular BI tools, making it accessible for data analysis and reporting.
DBT With Snowflake
By combining DBT with Snowflake, you can create a robust data analytics stack for efficient data modeling and transformation. The DBT Snowflake integration offers several benefits, as shown in the image below:

Hands-On

Now, let’s get started with this amazing data transformation tool. We are going to make use of DBT CLI for the sake of this blog and will use the vs code editor to write the scripts.
- Go to the DBT CLI installation page and you should already have git and python installed on your systems. You should also have a Snowflake account for the data warehouse which you can create using the given link – https://signup.snowflake.com/
- Run the command, pip install dbt-snowflake and it should install dbt core and all the dependencies on your system.

- Create a repository on your GitHub and clone it into your Documents folder.
git clone https://github.com/user/<project>.git and it’ll create an empty repository. - Go to that directory using terminal or PowerShell and initialize a dbt project.
run the command:dbt initthen it’ll ask about the project name so you can give it dbt_learnings and choose snowflake and enter your credentials.

- That’s it, these commands have now created a project structure for us and we can go to our dbt_learnings folder in vscode and see our project structure. There is also a ~/profiles.yml file created in the .dbt directory in Documents which contains the snowflake connection details. If your connection has changed, you can change your credentials at this location.
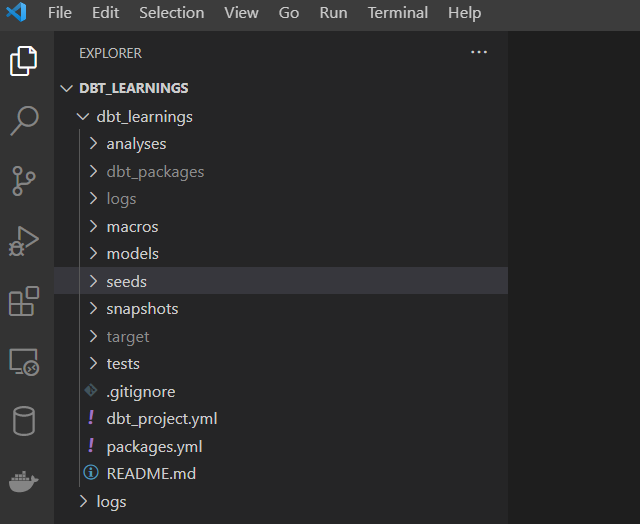
- Add your credentials to the profiles.yml file. The data warehouse, role, database, schema, credentials, etc.
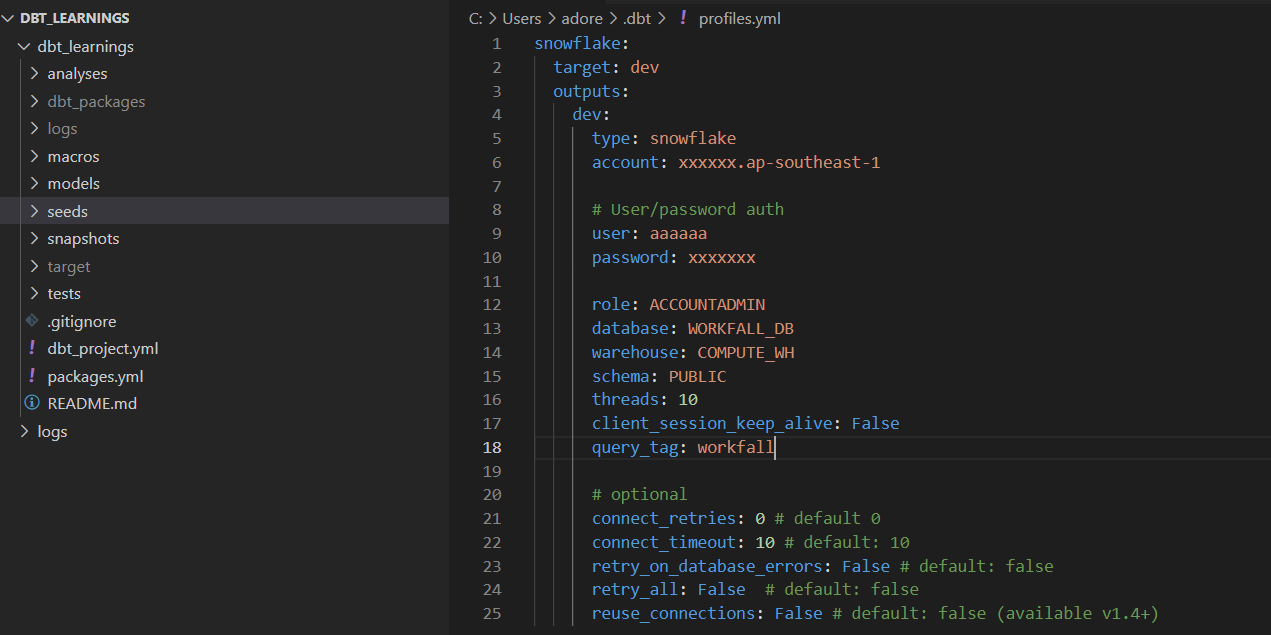
- Open the terminal and run this command:
dbt debug
This command will test the connection to Snowflake and let us know the status.

- After all the checks are passed, your dbt setup has been successful and you would now be able to create your own models and deploy them on Snowflake.
- Run the command: dbt run and it’ll run the demo models provided by dbt and create a new table/view on the snowflake. Here there are two models: my_first_dbt_model and my_second_dbt_model which are simple .SQL files. The dbt run command creates this SQL statement into DML and creates the table/view in the snowflake.

Models reflected in snowflake:

Understanding DBT Project Structure
- Models Directory: This directory serves as the central location for storing your data models. Each data model is defined in a separate file, typically using YAML syntax. These files contain the necessary information to define tables, views, or transformations in your data warehouse. The model’s directory helps keep your models organized and easily accessible.
model syntax: your_sql_file.sql
schema: schema.yml - Macros Directory: The macros directory is where you can store reusable code snippets called macros. Macros are like little helpers that allow you to define common logic or calculations once and reuse them across multiple models. For example, you can create a macro for calculating average sales or parsing dates. Storing macros in a dedicated directory promotes code reusability and helps maintain consistency throughout your data models.
- Tests Directory: In the tests directory, you can define tests to ensure the quality and integrity of your data. Tests are SQL-based assertions that check if certain conditions or expectations are met. For instance, you can create tests to validate that specific columns contain non-null values, check for data consistency across tables, or verify referential integrity. The tests directory helps you write and organize these assertions for each data model.
You can also define the tests in the schema.yml file and run them by executingdbt testcommand. - Analysis Directory: The analysis directory is optional but can be useful for storing SQL scripts or queries that are related to data analysis or ad hoc calculations. These scripts might not be part of the core data models but can assist in performing specific analyses or generating custom reports. Keeping them in a separate directory makes it easier to locate and manage analysis-related code.
- DBT Project Configuration: The DBT project configuration file, typically named dbt_project.yml, is a key file that contains various settings and configurations for your entire DBT project. It allows you to specify details such as the target database connection parameters, the default schema to use, the location of your models directory, and other project-specific settings. The project configuration file helps define the behavior and settings for your DBT project as a whole.
By organizing your DBT project using these directories and files, you create a structured framework that promotes modularity, reusability, and maintainability. This structure helps you and your team efficiently work with data models, tests, macros, analysis scripts, and documentation throughout the data modeling process.
Creating Your First Model
Now, we are going to define our model by defining our SQL query logic, adding a source from Snowflake, and executing this model.
- We have created an employee table that contains the names of the football employees in Snowflake and we are going to use this source to bring it into dbt, create a transformation model and test it as well.
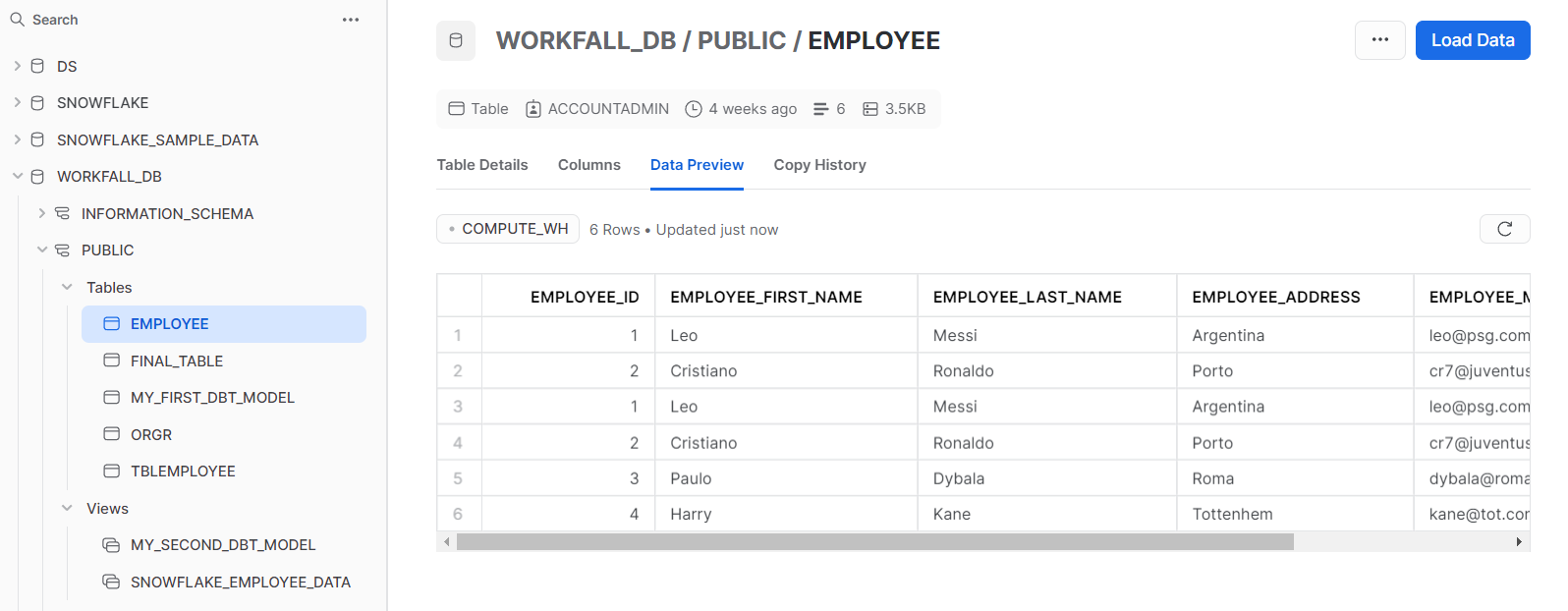
- Go to the models directory and create a new folder “snowflake_sample_data”. Create a schema.yml file and snowflake_employee_data.sql file.
- Write the table, schema, and details about the source table.

Here, snowflake_employee_data is the name through which this source will be referenced in dbt.
4. Create a model that selects from this data, and do some transformations along the way.

We would be selecting from four columns and would take only two employee_ids into consideration.
Also, we refer to this source as
{{ source(‘source_name’,’table_name’) }} which is a jinja macro to reference source.
5. Now let’s execute the dbt run command.
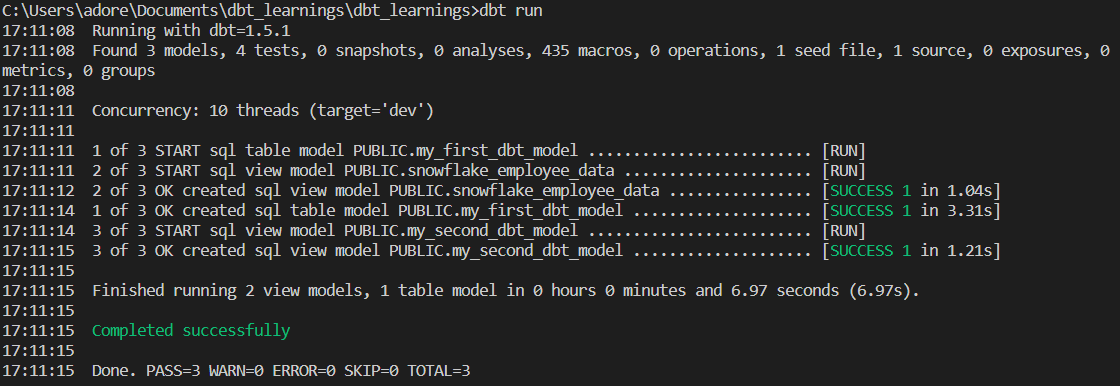
We can see that dbt has built this model and let’s verify it in snowflake.
And lastly, we can find that our models have been represented perfectly.
Conclusion
In this blog, we explored the fascinating world of DBT (Data Build Tool) and its impact on data analytics. We began by understanding the basics of DBT and its role in the modern data landscape. After a seamless installation process, we delved into the project structure, by demonstrating how to effectively organize DBT projects.
Creating our first model with DBT was an exciting experience, showcasing its ability to simplify complex transformations and enable scalable data models. DBT’s intuitive syntax and robust features empower us to focus on analysis and insights, rather than getting caught up in data engineering complexities.
DBT is gaining popularity across industries, bridging the gap between data engineers and analysts, and accelerating data-driven decision-making. As you continue your data journey, we will come up with more such use cases in our upcoming blogs. Happy DBT-ing!
Meanwhile…
If you are an aspiring Snowflake enthusiast and want to explore more about the above topics, here are a few of our blogs for your reference:
Stay tuned to get all the updates about our upcoming blogs on the cloud and the latest technologies.
Keep Exploring -> Keep Learning -> Keep Mastering
At Workfall, we strive to provide the best tech and pay opportunities to kickass coders around the world. If you’re looking to work with global clients, build cutting-edge products, and make big bucks doing so, give it a shot at workfall.com/partner today!
Frequently Asked Questions:
- Q: What exactly is DBT and why is it useful for data teams?
Reading Time: 8 minutesA: DBT (Data Build Tool) empowers data teams to transform raw data into structured insights using modular SQL models, dependency management, and built-in testing—making pipelines reliable, version-controlled, and collaborative.
- Q: How does DBT integrate with Snowflake in practical use cases?
Reading Time: 8 minutes A: The blog walks through connecting DBT with Snowflake, including project setup, DBT directory structure, and creating your first DBT model—all geared for analytics-ready outputs.
- Q: What does a hands-on DBT project look like in the tutorial?
Reading Time: 8 minutesA: You’ll see how to initialize a DBT project, understand its folder layout, and craft your initial model. This hands-on section turns abstract concepts into executable models for real data transformation.
- Q. How does DBT help in scaling and automating insights generation?
Reading Time: 8 minutesA: By stacking modular models, automating dependency resolution, and streamlining code deployment, DBT enables teams to reliably produce scalable, trustworthy data insights over time.
- Q: Who benefits most from learning DBT as described in the blog?
Reading Time: 8 minutesA: This guide is ideal for data engineers, analysts, or analytics engineers—basically anyone who works with raw data and needs to build repeatable, testable analytics workflows.


