
Assume you need to extract some information from the web. For example, you need some data on Manhattan. So, what exactly do you do? You simply copy-paste material from any website into your own document. But what if you need to extract a significant volume of data from a website as soon as possible? Copying and pasting will not work in this case! That’s when Web Scraping will come in handy.
Web scraping employs intelligent automation methods to collect thousands and millions of data sets in a lesser amount of time.
In this blog, we will explore Web Scraping, how it works, its challenges, and the Python libraries required for the process. We will also demonstrate step-by-step instructions on how to build a Web Scraper using Python.
In this blog, we will cover:
- What is Web Scraping?
- How does Web Scraping work?
- Challenges of Web Scraping
- Required Python libraries for the process
- Hands-on
- Conclusion
What is Web Scraping?
Web Scraping is basically the process of collecting and altering huge chunks of data from a website using computer software. It is majorly known to be an effective method for generating datasets for education purposes as well as it can also be used to scrape the required details from job sites to make it easy for us to search for jobs on a regular basis. The method extracts huge chunks of data from various sites in an automated fashion and the majority of the returned data is in an unstructured HTML format that is in turn transformed into a structured format in a database before it is used in the various applications.
How does Web Scraping work?

Web scraping helps us either retrieve all the data from a website or only the specific details required by a user. It is an effective practice of defining the structure for what is required before beginning the process of scraping a website so that only the required information is pulled out. For a web scraper to scrape a site, it first requires the URL of the site it needs to scrape. The scraper then extracts the required data from the HTML source code that is fetched to output the data in a user-defined format. The output data can be stored in a normal text format or in an Excel sheet or CSV file or even in a JSON file.
Challenges of Web Scraping
Web scraping will not work because of the following challenges:
- If the URL of the website you wish to scrape does not return a response code of 200 since the owner of the website disallows scraping.
- If the web page structure is complicated and dynamic, a web scraper might fail because one scraper is built for each site.
- If a website receives a large number of requests from a specific IP, the owner of the site can block that IP because of which the web scraper will not work.
- If a website consists of a CAPTCHA, then the web scraper will not work since CAPTCHA blocks all the automated software and robot access.
Required Python libraries for the process

- requests: the library allows us to send the API requests easily and efficiently and in-turn returns the required data. In our case, it returns the HTML source code of a website.
- bs4 & BeautifulSoup4: We need to install these libraries to convert the fetched HTML content into the BeautifulSoup or python objects.
- lxml parser: This parser deals well with unbroken HTML source code as well thus, is preferred to parse the HTML content over the default HTML parser.
Hands-on
In this blog, we will see in action the process of web scraping to fetch the required details. We will scrape an eCommerce test website provided by a web scraper to fetch the different items from the site. We will also have a look at a few of the conditions that can be applied to return data only as per the provided conditions. We will make use of the different libraries and a parser to parse the different HTML contents and finally, we will have a look at how we can automate the process of searching the top items on a frequent basis based on a provided interval and will then write the output in a text file.
We will be web scraping the below site. Ie. https://webscraper.io/test-sites. Navigate to this website and click on the E-commerce site.
Now, copy the new URL https://webscraper.io/test-sites/e-commerce/allinone. This is the new URL that we will be using to scrape.
Now, before we begin with the process of scraping, make sure to install the requests library using the below command.

Copy the URL of the site that you wish to scrape. The below code snippet will help you check if you can scrape a site. Once you execute the below code, check if you get a response code of 200. If you do, that means the following website is scrapable.

You can execute your python file using the below command.

If a site is scrapable, it will give you a response as shown in the image below.

Now that we know the following site is scrapable, let’s fetch the source of the website. We can make use of the text attribute to do so.

Execute the python file with the code in the above snippet and you will get to see the entire HTML source of the site that we are going to scrape.
Before we begin the process of scraping out the job posts, we need to install the libraries: beautifulsoup4, bs4, and lxml. You can do so using the below commands:



Now that we have the HTML source, we need to parse it into Python objects. To do so, we will make use of the BeautifulSoup library and the lxml parser.

After executing the code in the above snippet, we will have the parsed HTML source code converted into the BeautifulSoup object.

Now that we are ready with all the prerequisites, navigate back to the URL that you wish to scrape.

We need to collect specific data for our parser code from the HTML source code. Either press F12 on the keyboard or right-click on the site and click on Inspect Element. You will see the screen as shown in the image below. Now, we need to filter out the top items divs so that we can get the class name and the tag name (that we will use to scrape the site). Note down the class names and the tag names or double-click on it in the Elements pane and copy the class names.
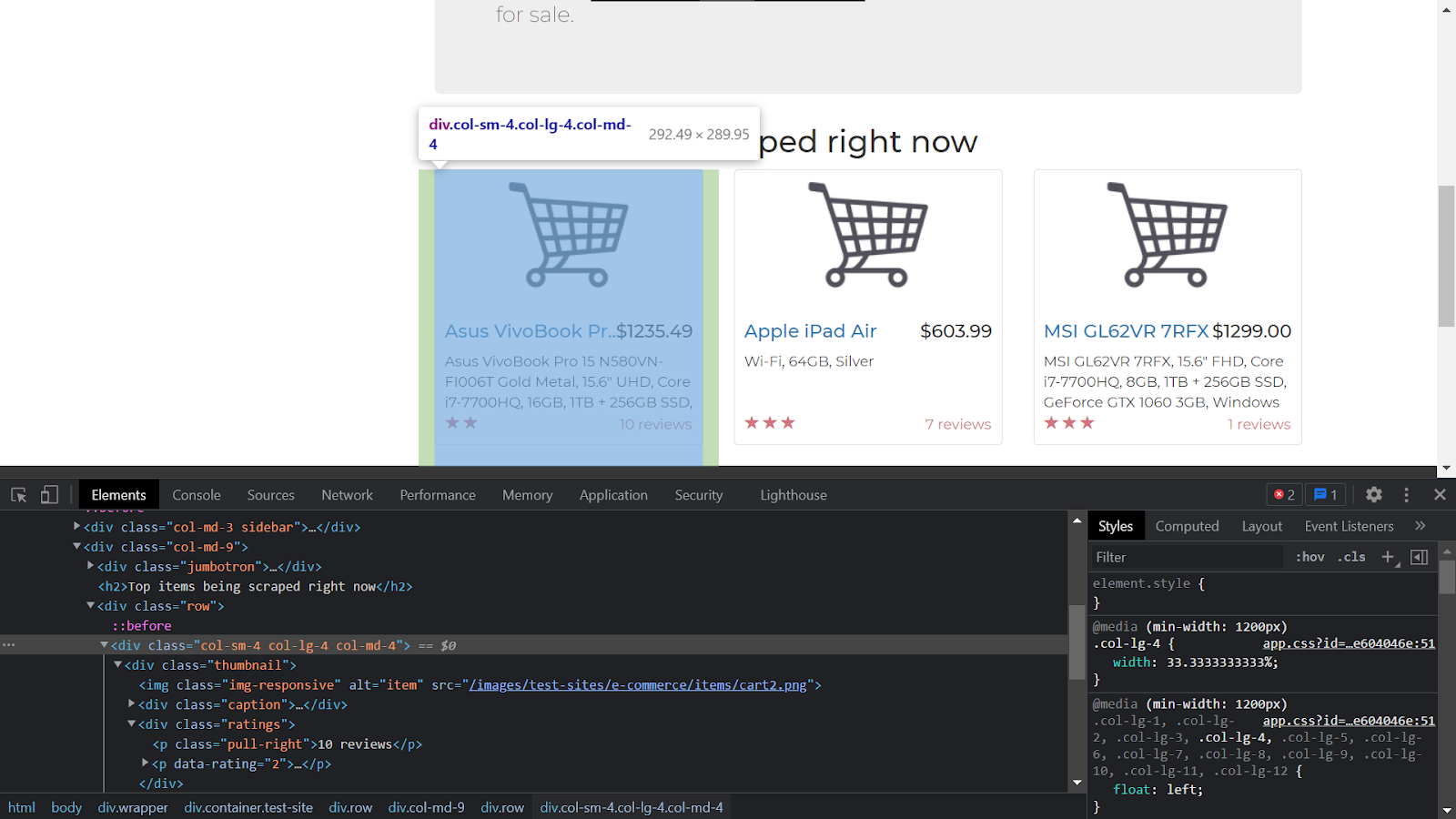
Now, the same class name has been used for all the top items. In order to get all the items, we will make use of the find_all() method passing the ‘<div>’ tag and the class name that we copied above as the values in-turn to fetch the list of items.
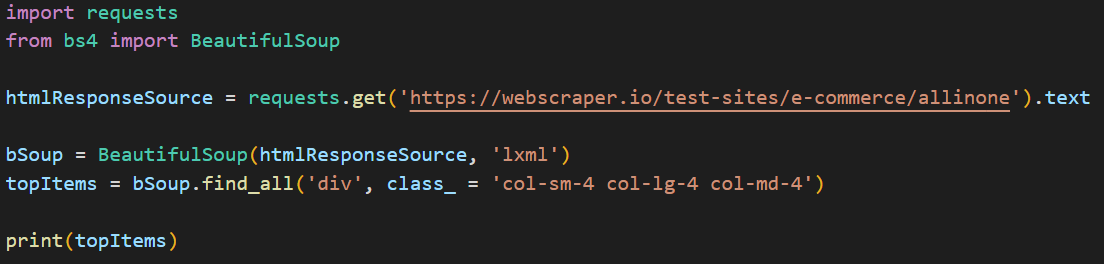
Executing the above code will give you the HTML source of all the top items on that site as shown in the image below.

Now, to filter out our search, fetch only what is required, and to make things readable in plain english, we will inspect the specific things on the site and get the class names and the tags for the same. In the below image, we see that the product name exists in an <a> tag with the class name as ‘title’.
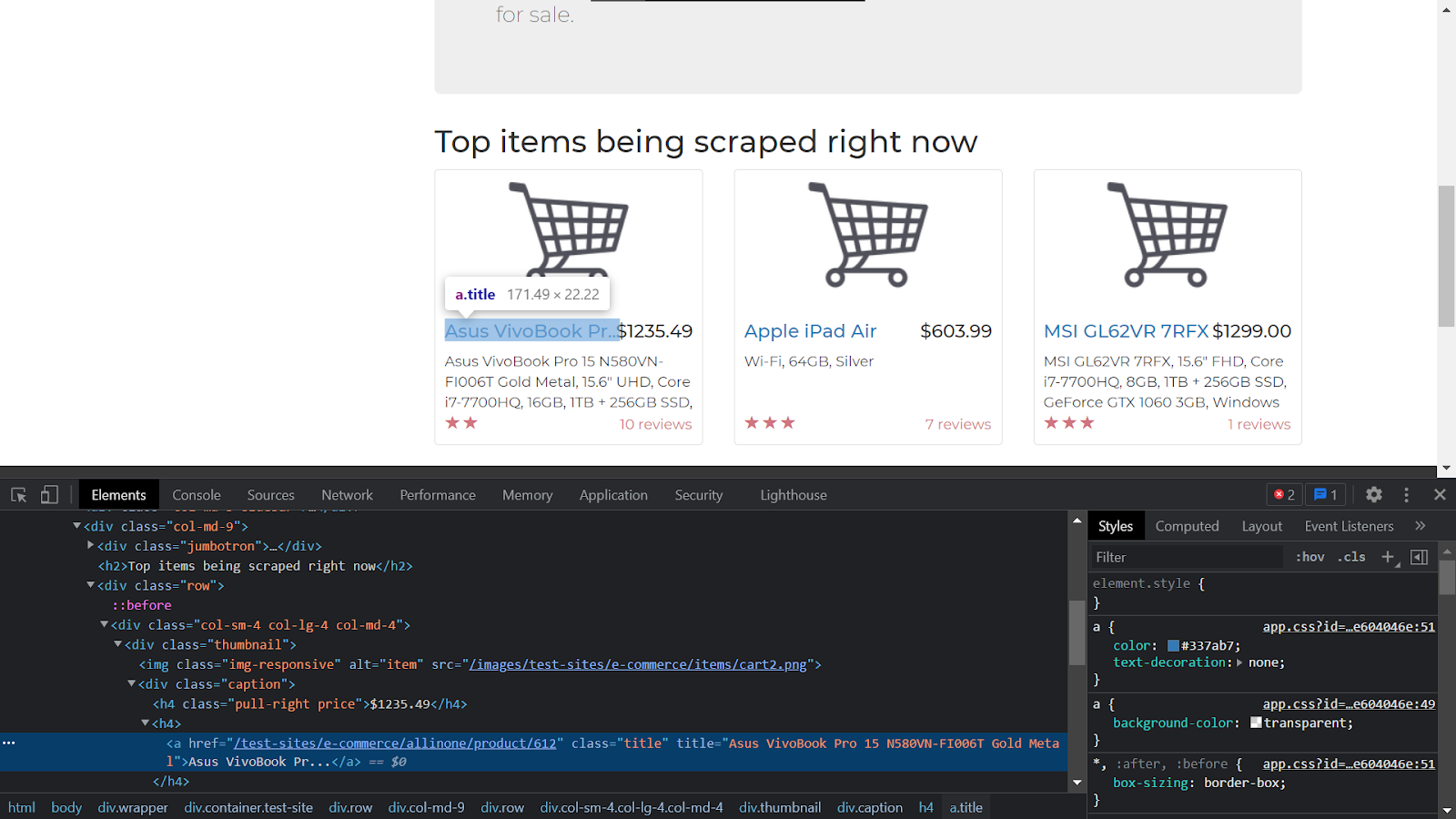
When we inspect the description for an item, we see that the description exists in a <p> tag and with the class name as ‘description’.

Similarly, we fetch the product price that exists in an <h4> tag as shown in the image below.

Finally, we will inspect the number of reviews for a product that exists in a <p> tag.

Now that we have noted down the required class names along with the tag names, we can fetch the required details using the below class names and the tag names.

We already have a list of all the top items so in order to fetch each item and its other details, we will iterate over the list and use the find() method passing in the attributes ‘HTML tag and the class name attached to it’ for each item to get the required details. In the below snippet, we can get the product name of all the top items.

After you execute the above code, you will see the names of all the top products.

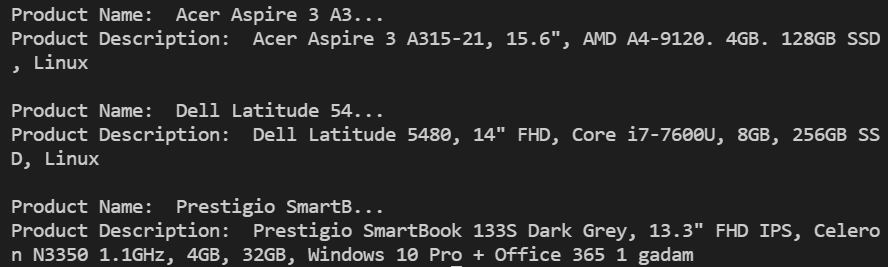
In the below snippet, we can get the description of each product attached to all the items in the list of items.
After you execute the above code, you will see the names of all the top products along with the product description.
In the below snippet, we then fetch the product price using its class name and the tag that we fetched above using the inspect element tool of the browser.
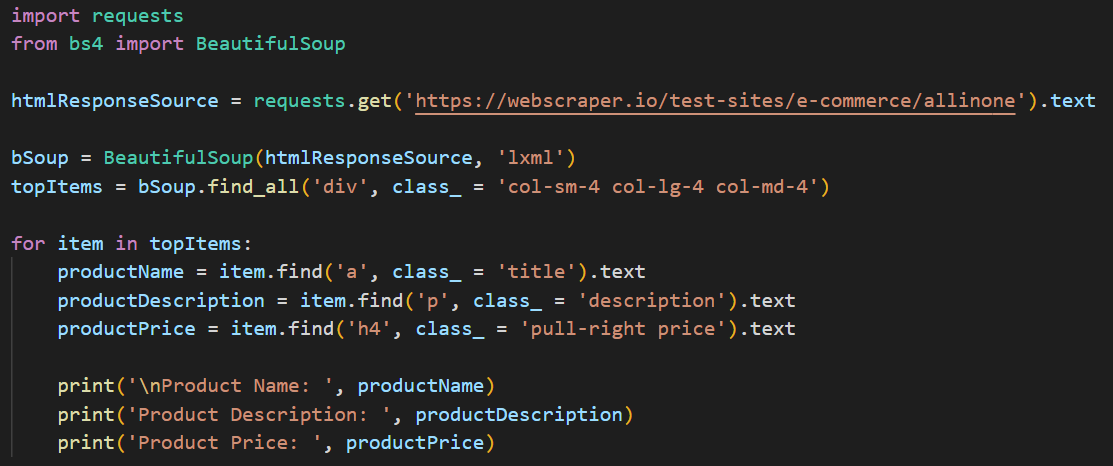
You can see the product price for all the top products in the list of the items in the image below.
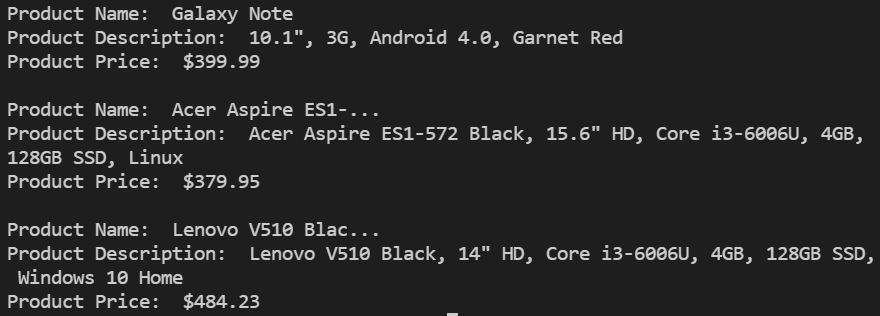
You can use the below code to fetch the reviews count for each product in the list.

After you execute the above code, you will see the reviews for all the products in the list of all the items.

Now, let’s fetch the product link. We can do so by fetching the link from the href attribute from the <a> tag.

On executing the above code in the snippet, you will get to see the product links as well for each of the items in the list of item.
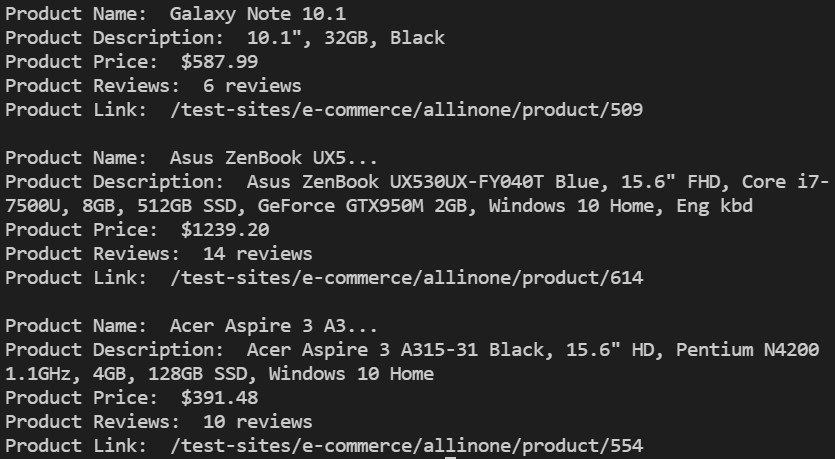
Now that we have scraped all the required details, let’s make some alterations in the code base. We will now generalize the code in order to return only the items that have reviews less than 5.

On executing the above code, you will see the results as only the items that have the reviews less than 5.

We will alter the code base to return the items that either has product reviews greater than 5 or product price greater than 1000.

After executing the above code, you will get the product links as well for all the products.

To customize it even further, we will alter the same code base to add the output results in a text file so that it becomes easy for us to search and look for a product of our choice.

Executing the above code will create a new file in the same folder where your code exists with all the top items as per the conditions applied in a much better and readable format.

Now, let’s alter the code base to automate the process of searching for top items. We will make use of the time library to make use of the sleep method that will execute our searchForTopItems() function looking for the top items at an interval of the assigned time and will in-turn store the output results in a text file.
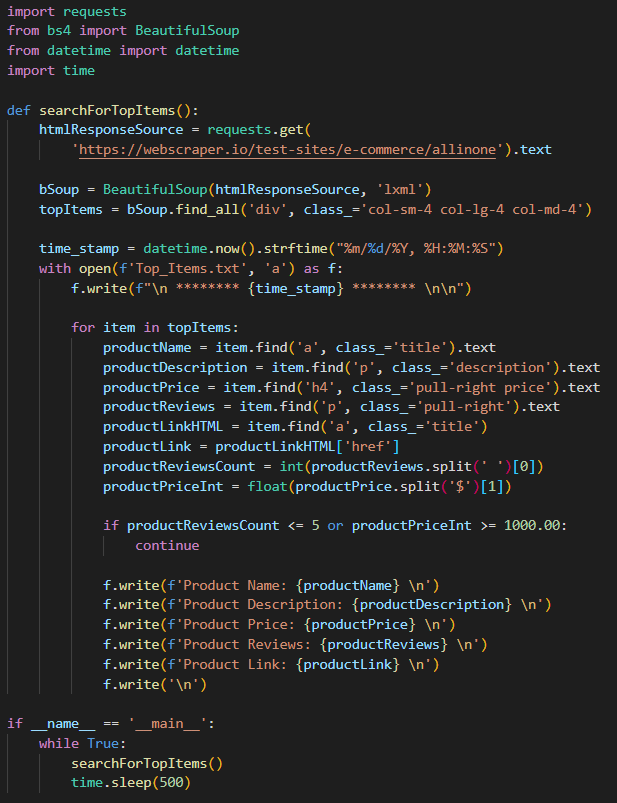
Timestamps make it easy for us to check if our item searcher code is scraping the sites properly and returning the desired results at a fixed interval.

Conclusion
In this blog, we saw in action the process of web scraping to fetch the required details. We scraped an Ecommerce test website provided by a web scraper to fetch the different items from the site. We also had a look at a few of the conditions that can be applied to return data only as per the provided conditions. We made use of the different libraries and a parser to parse the different HTML contents and finally we had a look at how we can automate the process of searching the top items on a frequent basis based on a provided interval and then wrote down the output in a text file. Stay tuned to keep getting all updates about our upcoming new blogs on AWS and relevant technologies.
Meanwhile …
Keep Exploring -> Keep Learning -> Keep Mastering
This blog is part of our effort towards building a knowledgeable and kick-ass tech community. At Workfall, we strive to provide the best tech and pay opportunities to AWS-certified talents. If you’re looking to work with global clients, build kick-ass products while making big bucks doing so, give it a shot at workfall.com/partner today.


